A tájékozatlan keresés az általános célú keresési algoritmusok egy osztálya, amely nyers erővel működik. A tájékozatlan keresési algoritmusok nem rendelkeznek további információval az állapotról vagy a keresési térről azon kívül, hogy hogyan kell áthaladni a fán, ezért ezt vakkeresésnek is nevezik.
Az alábbiakban felsoroljuk a tájékozatlan keresési algoritmusok különféle típusait:
1. Keresés az első helyen:
- A szélesség-első keresés a leggyakoribb keresési stratégia egy fa vagy grafikon bejárására. Ez az algoritmus szélességben keres egy fában vagy gráfban, ezért szélesség szerinti keresésnek nevezik.
- A BFS algoritmus a fa gyökércsomópontjától kezdi meg a keresést, és kibővíti az összes utódcsomópontot az aktuális szinten, mielőtt a következő szint csomópontjaira lépne.
- A szélesség-első keresési algoritmus egy példa az általános gráfos keresési algoritmusra.
- Széleskörű keresés FIFO-sor adatszerkezettel megvalósítva.
Előnyök:
- A BFS megoldást kínál, ha létezik ilyen megoldás.
- Ha egy adott problémára több megoldás is létezik, akkor a BFS azt a minimális megoldást nyújtja, amely a legkevesebb lépést igényel.
Hátrányok:
- Sok memóriát igényel, mivel a fa minden szintjét a memóriába kell menteni a következő szint bővítéséhez.
- A BFS-nek sok időre van szüksége, ha a megoldás messze van a gyökércsomóponttól.
Példa:
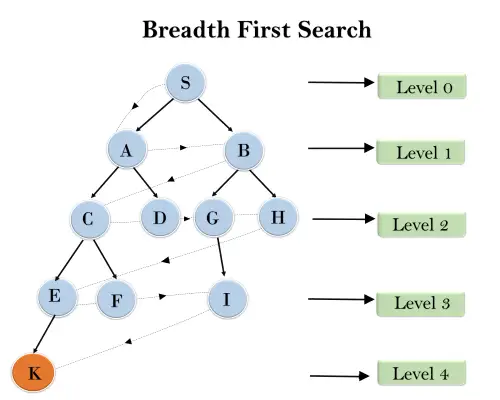
Az alábbi fastruktúrában bemutattuk a fa bejárását BFS algoritmussal az S gyökércsomóponttól a K célcsomópontig. A BFS kereső algoritmus rétegekben halad, tehát a pontozott nyíllal jelzett útvonalat fogja követni, és a a bejárt út a következő lesz:
S---> A--->B---->C--->D---->G--->H--->E---->F---->I---->K
Időbeli összetettség: A BFS algoritmus időbeli összetettsége a BFS-ben a legsekélyebb csomópontig bejárt csomópontok számával érhető el. Ahol d = a legsekélyebb megoldás mélysége és b egy csomópont minden állapotban.
T(b) = 1+b2+b3+.......+ bd= O (bd)
A tér összetettsége: A BFS algoritmus térbeli összetettségét a határ memóriamérete adja meg, amely O(bd).
Teljesség: A BFS kész, ami azt jelenti, hogy ha a legsekélyebb célcsomópont valamilyen véges mélységben van, akkor a BFS megtalálja a megoldást.
jvm
Optimalitás: A BFS akkor optimális, ha az útköltség a csomópont mélységének nem csökkenő függvénye.
2. Mélység-első keresés
- A mélységi keresés egy rekurzív algoritmus egy fa vagy gráf adatszerkezet bejárására.
- Mélység-első keresésnek nevezik, mert a gyökércsomóponttól indul, és minden utat követ a legnagyobb mélységű csomópontig, mielőtt a következő útvonalra lépne.
- Az elosztott fájlrendszer egy verem adatszerkezetet használ a megvalósításához.
- A DFS-algoritmus folyamata hasonló a BFS-algoritmushoz.
Megjegyzés: A Backtracking egy algoritmus technika, amely az összes lehetséges megoldást rekurzió segítségével megtalálja.
Előny:
- A DFS-nek nagyon kevesebb memóriára van szüksége, mivel csak a gyökércsomóponttól az aktuális csomópontig tartó útvonalon lévő csomópontok veremét kell tárolnia.
- Kevesebb időbe telik elérni a célcsomópontot, mint a BFS algoritmusnak (ha a megfelelő úton halad).
Hátrány:
- Fennáll annak lehetősége, hogy sok állapot ismétlődik, és nincs garancia a megoldás megtalálására.
- A DFS-algoritmus a mélyre ható kereséshez megy, és néha a végtelen hurokba lép.
Példa:
Az alábbi keresési fában megmutattuk a mélységi keresés menetét, és ez a következő sorrendet fogja követni:
Gyökér csomópont ---> Bal csomópont ----> jobb csomópont.
Az S gyökércsomóponttól kezdi meg a keresést, és bejárja az A-t, majd B-t, majd D-t és E-t, az E bejárása után visszalép a fán, mivel E-nek nincs másik utódja, és a célcsomópont továbbra sem található. A visszalépés után áthalad a C, majd a G csomóponton, és itt véget ér, ahogy megtalálta a célcsomópontot.

Teljesség: A DFS keresési algoritmus véges állapottéren belül teljes, mivel minden csomópontot kibővít egy korlátozott keresési fán belül.
Időbeli összetettség: A DFS időbonyolultsága megegyezik az algoritmus által bejárt csomóponttal. Ezt adja:
T(n)=1+n2+ n3+.........+ nm=O(nm)
Ahol m = bármely csomópont maximális mélysége, és ez sokkal nagyobb lehet, mint d (legsekélyebb megoldási mélység)
A tér összetettsége: A DFS-algoritmusnak csak egyetlen útvonalat kell tárolnia a gyökércsomóponttól, ezért a DFS térbonyolultsága megegyezik a peremhalmaz méretével, ami Ról ről .
Optimális: A DFS keresési algoritmus nem optimális, mivel nagy számú lépést vagy magas költségeket generálhat a célcsomópont eléréséhez.
3. Mélységben korlátozott keresési algoritmus:
A mélységben korlátozott keresési algoritmus hasonló a mélységben végzett kereséshez, előre meghatározott korláttal. A mélységben korlátozott keresés megoldhatja a végtelen út hátrányát a Mélység-első keresésben. Ebben az algoritmusban a mélységhatárnál lévő csomópont úgy kezeli, hogy nincs további utódcsomópontja.
A mélységben korlátozott keresést két meghibásodási feltétellel lehet befejezni:
konvertálja a stringet int-re java-ban
- Szabványos hibaérték: Azt jelzi, hogy a problémának nincs megoldása.
- Cutoff error value: Egy adott mélységhatáron belül nem ad megoldást a problémára.
Előnyök:
A mélységben korlátozott keresés memóriahatékony.
Hátrányok:
- A mélységben korlátozott keresés hátránya is a hiányosság.
- Nem biztos, hogy optimális, ha a problémának több megoldása is van.
Példa:

Teljesség: A DLS keresési algoritmus akkor teljes, ha a megoldás a mélységhatár felett van.
Időbeli összetettség: A DLS algoritmus időbonyolultsága az O(bℓ) .
A tér összetettsége: A DLS algoritmus térbonyolultsága O (b�ℓ) .
Optimális: A mélységben korlátozott keresés a DFS speciális esetének tekinthető, és még akkor sem optimális, ha ℓ>d.
részleges származék latexben
4. Egységes költségű keresési algoritmus:
Az egységes költségű keresés egy keresési algoritmus, amelyet súlyozott fa vagy gráf bejárására használnak. Ez az algoritmus akkor lép életbe, ha minden élhez eltérő költség áll rendelkezésre. Az egységes költségű keresés elsődleges célja, hogy megtalálja a legalacsonyabb halmozott költségű célcsomóponthoz vezető utat. Az egységes költségű keresés kibővíti a csomópontokat a gyökércsomópontból származó útvonalköltségük szerint. Bármilyen gráf/fa megoldására használható, ahol az optimális költség igényes. A prioritási sor egy egységes költségű keresési algoritmust valósít meg. Maximális prioritást ad a legalacsonyabb halmozott költségnek. Az egységes költségkeresés egyenértékű a BFS algoritmussal, ha az összes él elérési költsége azonos.
Előnyök:
- Az egységes költségkeresés azért optimális, mert minden állapotnál a legalacsonyabb költségű utat választjuk.
Hátrányok:
- Nem törődik a keresés lépéseinek számával, és csak az útvonalköltségekkel foglalkozik. Emiatt ez az algoritmus egy végtelen hurokban ragadhat.
Példa:

Teljesség:
Az egységes költségű keresés befejeződött, például ha van megoldás, az UCS megtalálja.
Időbeli összetettség:
Legyen C* az optimális megoldás költsége , és e minden lépés, hogy közelebb kerüljünk a célcsomóponthoz. Ekkor a lépések száma = C*/ε+1. Itt a +1-et vettük, mivel a 0 állapotból indulunk ki, és a C*/ε-ig tartunk.
Ezért az egységes költségű keresés legrosszabb időbeli összetettsége az O(b1 + [C*/e])/ .
A tér összetettsége:
Ugyanez a logika vonatkozik a tér összetettségére, tehát az egységes költségű keresés legrosszabb eseti összetettsége O(b1 + [C*/e]) .
Optimális:
Az egységes költségű keresés mindig optimális, mivel csak a legalacsonyabb útköltséggel rendelkező útvonalat választja ki.
5. Iteratív mélyítő mélység-első keresés:
Az iteratív mélyítő algoritmus DFS és BFS algoritmusok kombinációja. Ez a keresési algoritmus megtalálja a legjobb mélységhatárt, és fokozatosan növeli a határt, amíg meg nem talál egy célt.
java prioritási sor
Ez az algoritmus mélységi keresést hajt végre egy bizonyos „mélységi határig”, és minden iteráció után folyamatosan növeli a mélységhatárt, amíg meg nem találja a célcsomópontot.
Ez a keresési algoritmus egyesíti a Breadth-first keresés gyors keresésének és a mélységi keresés memóriahatékonyságának előnyeit.
Az iteratív keresési algoritmus hasznos információ nélküli keresés, ha nagy a keresési terület, és a célcsomópont mélysége ismeretlen.
Előnyök:
- Egyesíti a BFS és DFS keresési algoritmus előnyeit a gyors keresés és a memória hatékonysága tekintetében.
Hátrányok:
- Az IDDFS fő hátránya, hogy megismétli az előző fázis összes munkáját.
Példa:
A következő fastruktúra az iteratív mélyítő mélység-első keresést mutatja. Az IDDFS algoritmus különféle iterációkat hajt végre, amíg meg nem találja a célcsomópontot. Az algoritmus által végrehajtott iteráció a következő:

1. iteráció -----> A
2. iteráció ----> A, B, C
3. iteráció ------>A, B, D, E, C, F, G
4. iteráció ------>A, B, D, H, I, E, C, F, K, G
A negyedik iterációban az algoritmus megkeresi a célcsomópontot.
Teljesség:
Ez az algoritmus akkor teljes, ha az elágazási tényező véges.
Időbeli összetettség:
Tegyük fel, hogy b az elágazási tényező és a mélység d, akkor a legrosszabb eset időbonyolultsága O(bd) .
hogyan tudhatod meg, hogy valaki letiltott-e téged androidon
A tér összetettsége:
Az IDDFS térbeli összetettsége az lesz O(bd) .
Optimális:
Az IDDFS algoritmus akkor optimális, ha az útköltség a csomópont mélységének nem csökkenő függvénye.
6. Kétirányú keresési algoritmus:
A kétirányú keresési algoritmus két egyidejű keresést futtat, az egyik kezdeti állapotot előrekeresőnek, a másikat pedig a célcsomópontból visszafelé keresésnek nevezik, hogy megtalálja a célcsomópontot. A kétirányú keresés egyetlen keresési gráfot lecserél két kis részgráfra, amelyekben az egyik a kezdeti csúcstól, a másik pedig a célcsúcstól kezdi a keresést. A keresés leáll, ha ez a két grafikon metszi egymást.
A kétirányú keresés olyan keresési technikákat használhat, mint a BFS, DFS, DLS stb.
Előnyök:
- A kétirányú keresés gyors.
- A kétirányú keresés kevesebb memóriát igényel
Hátrányok:
- A kétirányú keresési fa megvalósítása nehézkes.
Példa:
Az alábbi keresési fában kétirányú keresési algoritmust alkalmazunk. Ez az algoritmus egy gráfot/fát két részgráfra oszt. Az 1-es csomóponttól indul előrefelé és a 16-os célcsomóponttól indul visszafelé.
Az algoritmus a 9-es csomópontnál ér véget, ahol két keresés találkozik.

Teljesség: A kétirányú keresés akkor teljes, ha mindkét keresésben BFS-t használunk.
Időbeli összetettség: A BFS használatával végzett kétirányú keresés időbonyolultsága O(bd) .
A tér összetettsége: A kétirányú keresés térbonyolultsága az O(bd) .
Optimális: A kétirányú keresés optimális.