A szó ' Trie ' egy részlet a ' szóból visszakeresés '. A Trie egy rendezett fa alapú adatstruktúra, amely a karakterláncok halmazát tárolja. A mutatók száma megegyezik az egyes csomópontokban lévő ábécé karaktereinek számával. Kereshet egy szót a szótárban a szó előtagja segítségével. Például, ha feltételezzük, hogy minden karakterlánc a ' a ' nak nek ' Val vel ' az angol ábécében minden trie csomópontnak maximuma lehet 26 pontokat.
python mérete
A Trie-t digitális faként vagy előtagfaként is ismerik. Egy csomópont pozíciója a Trie-ben határozza meg azt a kulcsot, amelyhez az adott csomópont kapcsolódik.
A Trie tulajdonságai a karakterlánc készletéhez:
- A trie gyökércsomópontja mindig a nullcsomópontot jelenti.
- A csomópontok minden gyermeke ábécé szerint van rendezve.
- Minden csomópontnak maximum lehet 26 gyerekek (A-tól Z-ig).
- Minden csomópont (a gyökér kivételével) az ábécé egy betűjét tárolhatja.
Az alábbi diagram a csengő, a medve, a furat, az ütő, a labda, a stop, a készlet és a verem trie ábrázolását mutatja.
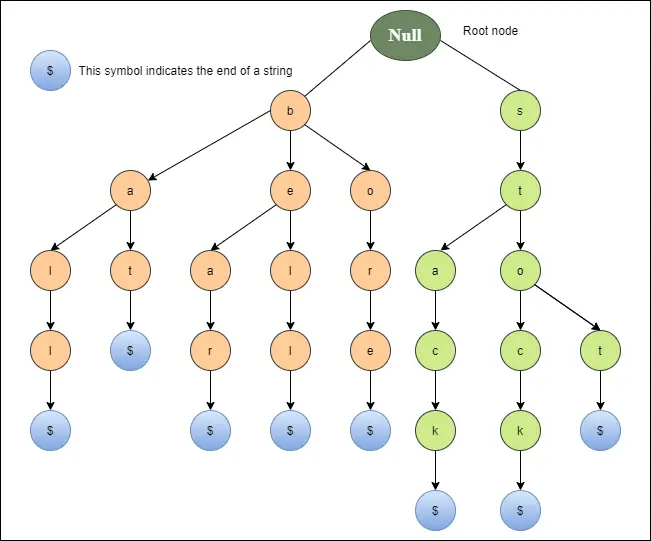
A Trie alapműveletei
Három művelet van a Trie-ben:
- Csomópont beillesztése
- Csomópont keresése
- Csomópont törlése
Csomópont beszúrása a Trie-be
Az első művelet egy új csomópont beszúrása a trie-be. Mielőtt elkezdené a megvalósítást, fontos megérteni néhány pontot:
- A beviteli kulcs (szó) minden betűje egyediként kerül beillesztésre a Trie_node-ba. Vegye figyelembe, hogy a gyerekek a Trie csomópontok következő szintjére mutatnak.
- A kulcskarakter-tömb a gyermekek indexeként működik.
- Ha a jelenlegi csomópont már rendelkezik hivatkozással az aktuális betűre, állítsa a jelenlegi csomópontot erre a hivatkozott csomópontra. Ellenkező esetben hozzon létre egy új csomópontot, állítsa be a betűt a jelenlegi betűvel egyenlőre, és indítsa el a jelenlegi csomópontot ezzel az új csomóponttal.
- A karakter hossza határozza meg a próbálkozás mélységét.
Új csomópont beszúrásának megvalósítása a Trie-ben
public class Data_Trie { private Node_Trie root; public Data_Trie(){ this.root = new Node_Trie(); } public void insert(String word){ Node_Trie current = root; int length = word.length(); for (int x = 0; x <length; x++){ char l="word.charAt(x);" node_trie node="current.getNode().get(L);" if (node="=" null){ (); current.getnode().put(l, node); } current="node;" current.setword(true); < pre> <h3>Searching a node in Trie</h3> <p>The second operation is to search for a node in a Trie. The searching operation is similar to the insertion operation. The search operation is used to search a key in the trie. The implementation of the searching operation is shown below.</p> <p>Implementation of search a node in the Trie</p> <pre> class Search_Trie { private Node_Trie Prefix_Search(String W) { Node_Trie node = R; for (int x = 0; x <w.length(); x++) { char curletter="W.charAt(x);" if (node.containskey(curletter)) node="node.get(curLetter);" } else return null; node; public boolean search(string w) node_trie !="null" && node.isend(); < pre> <h3>Deletion of a node in the Trie</h3> <p>The Third operation is the deletion of a node in the Trie. Before we begin the implementation, it is important to understand some points:</p> <ol class="points"> <li>If the key is not found in the trie, the delete operation will stop and exit it.</li> <li>If the key is found in the trie, delete it from the trie.</li> </ol> <p> <strong>Implementation of delete a node in the Trie</strong> </p> <pre> public void Node_delete(String W) { Node_delete(R, W, 0); } private boolean Node_delete(Node_Trie current, String W, int Node_index) { if (Node_index == W.length()) { if (!current.isEndOfWord()) { return false; } current.setEndOfWord(false); return current.getChildren().isEmpty(); } char A = W.charAt(Node_index); Node_Trie node = current.getChildren().get(A); if (node == null) { return false; } boolean Current_Node_Delete = Node_delete(node, W, Node_index + 1) && !node.isEndOfWord(); if (Current_Node_Delete) { current.getChildren().remove(A); return current.getChildren().isEmpty(); } return false; } </pre> <h2>Applications of Trie</h2> <p> <strong>1. Spell Checker</strong> </p> <p>Spell checking is a three-step process. First, look for that word in a dictionary, generate possible suggestions, and then sort the suggestion words with the desired word at the top.</p> <p>Trie is used to store the word in dictionaries. The spell checker can easily be applied in the most efficient way by searching for words on a data structure. Using trie not only makes it easy to see the word in the dictionary, but it is also simple to build an algorithm to include a collection of relevant words or suggestions.</p> <p> <strong>2. Auto-complete</strong> </p> <p>Auto-complete functionality is widely used on text editors, mobile applications, and the Internet. It provides a simple way to find an alternative word to complete the word for the following reasons.</p> <ul> <li>It provides an alphabetical filter of entries by the key of the node.</li> <li>We trace pointers only to get the node that represents the string entered by the user.</li> <li>As soon as you start typing, it tries to complete your input.</li> </ul> <p> <strong>3. Browser history</strong> </p> <p>It is also used to complete the URL in the browser. The browser keeps a history of the URLs of the websites you've visited.</p> <h2>Advantages of Trie</h2> <ol class="points"> <li>It can be insert faster and search the string than hash tables and binary search trees.</li> <li>It provides an alphabetical filter of entries by the key of the node.</li> </ol> <h2>Disadvantages of Trie</h2> <ol class="points"> <li>It requires more memory to store the strings.</li> <li>It is slower than the hash table.</li> </ol> <h2>Complete program in C++</h2> <pre> #include #include #include #define N 26 typedef struct TrieNode TrieNode; struct TrieNode { char info; TrieNode* child[N]; int data; }; TrieNode* trie_make(char info) { TrieNode* node = (TrieNode*) calloc (1, sizeof(TrieNode)); for (int i = 0; i <n; i++) node → child[i]="NULL;" data="0;" info="info;" return node; } void free_trienode(trienode* node) { for(int i="0;" < n; if (node !="NULL)" free_trienode(node child[i]); else continue; free(node); trie loop start trienode* trie_insert(trienode* flag, char* word) temp="flag;" for (int word[i] ; int idx="(int)" - 'a'; (temp child[idx]="=" null) child[idx]; }trie flag; search_trie(trienode* position="word[i]" child[position]="=" 0; child[position]; && 1) 1; check_divergence(trienode* len="strlen(word);" (len="=" 0) last_index="0;" len; child[position]) j="0;" <n; j++) (j child[j]) + break; last_index; find_longest_prefix(trienode* (!word || word[0]="=" '�') null; longest_prefix="(char*)" calloc 1, sizeof(char)); longest_prefix[i]="word[i];" longest_prefix[len]="�" branch_idx="check_divergence(flag," longest_prefix) (branch_idx>= 0) { longest_prefix[branch_idx] = '�'; longest_prefix = (char*) realloc (longest_prefix, (branch_idx + 1) * sizeof(char)); } return longest_prefix; } int data_node(TrieNode* flag, char* word) { TrieNode* temp = flag; for (int i = 0; word[i]; i++) { int position = (int) word[i] - 'a'; if (temp → child[position]) { temp = temp → child[position]; } } return temp → data; } TrieNode* trie_delete(TrieNode* flag, char* word) { if (!flag) return NULL; if (!word || word[0] == '�') return flag; if (!data_node(flag, word)) { return flag; } TrieNode* temp = flag; char* longest_prefix = find_longest_prefix(flag, word); if (longest_prefix[0] == '�') { free(longest_prefix); return flag; } int i; for (i = 0; longest_prefix[i] != '�'; i++) { int position = (int) longest_prefix[i] - 'a'; if (temp → child[position] != NULL) { temp = temp → child[position]; } else { free(longest_prefix); return flag; } } int len = strlen(word); for (; i <len; i++) { int position="(int)" word[i] - 'a'; if (temp → child[position]) trienode* rm_node="temp→child[position];" temp child[position]="NULL;" free_trienode(rm_node); } free(longest_prefix); return flag; void print_trie(trienode* flag) (!flag) return; printf('%c ', temp→info); for (int i="0;" < n; print_trie(temp child[i]); search(trienode* flag, char* word) printf('search the word %s: word); (search_trie(flag, 0) printf('not found
'); else printf('found!
'); main() flag="trie_make('�');" 'oh'); 'way'); 'bag'); 'can'); search(flag, 'ohh'); 'ways'); print_trie(flag); printf('
'); printf('deleting 'hello'...
'); 'can'...
'); free_trienode(flag); 0; pre> <p> <strong>Output</strong> </p> <pre> Search the word ohh: Not Found Search the word bag: Found! Search the word can: Found! Search the word ways: Not Found Search the word way: Found! → h → e → l → l → o → w → a → y → i → t → e → a → b → a → g → c → a → n deleting the word 'hello'... → w → a → y → h → i → t → e → a → b → a → g → c → a → n deleting the word 'can'... → w → a → y → h → i → t → e → a → b → a → g </pre> <hr></len;></n;></pre></w.length();></pre></length;> A Trie alkalmazásai
1. Helyesírás-ellenőrző
A helyesírás-ellenőrzés három lépésből áll. Először keresse meg a szót a szótárban, generáljon lehetséges javaslatokat, majd rendezze a javasolt szavakat úgy, hogy a kívánt szó felül legyen.
negyedévben az üzleti életben
A Trie a szó tárolására szolgál a szótárakban. A helyesírás-ellenőrző egyszerűen a leghatékonyabb módon alkalmazható, ha egy adatszerkezeten keres szavakat. A trie használata nem csak megkönnyíti a szó megtekintését a szótárban, hanem egyszerű algoritmust is felépíteni a releváns szavak vagy javaslatok gyűjteményébe.
fatérkép
2. Automatikus kiegészítés
Az automatikus kiegészítést széles körben használják szövegszerkesztőkben, mobilalkalmazásokban és az interneten. A következő okok miatt egyszerű módot kínál arra, hogy alternatív szót találjon a szó kiegészítésére.
- A bejegyzések ábécé szerinti szűrőjét biztosítja a csomópont kulcsa alapján.
- A mutatókat csak azért követjük nyomon, hogy megkapjuk azt a csomópontot, amely a felhasználó által beírt karakterláncot reprezentálja.
- Amint elkezd gépelni, megpróbálja befejezni a bevitelt.
3. Böngészőelőzmények
Az URL kitöltésére is szolgál a böngészőben. A böngésző megőrzi a meglátogatott webhelyek URL-címeinek előzményeit.
A Trie előnyei
- Gyorsabban beszúrható és kereshet a karakterláncban, mint a hash táblák és a bináris keresőfák.
- A bejegyzések ábécé szerinti szűrőjét biztosítja a csomópont kulcsa alapján.
A Trie hátrányai
- A karakterláncok tárolása több memóriát igényel.
- Lassabb, mint a hash tábla.
Teljes program C++ nyelven
#include #include #include #define N 26 typedef struct TrieNode TrieNode; struct TrieNode { char info; TrieNode* child[N]; int data; }; TrieNode* trie_make(char info) { TrieNode* node = (TrieNode*) calloc (1, sizeof(TrieNode)); for (int i = 0; i <n; i++) node → child[i]="NULL;" data="0;" info="info;" return node; } void free_trienode(trienode* node) { for(int i="0;" < n; if (node !="NULL)" free_trienode(node child[i]); else continue; free(node); trie loop start trienode* trie_insert(trienode* flag, char* word) temp="flag;" for (int word[i] ; int idx="(int)" - \'a\'; (temp child[idx]="=" null) child[idx]; }trie flag; search_trie(trienode* position="word[i]" child[position]="=" 0; child[position]; && 1) 1; check_divergence(trienode* len="strlen(word);" (len="=" 0) last_index="0;" len; child[position]) j="0;" <n; j++) (j child[j]) + break; last_index; find_longest_prefix(trienode* (!word || word[0]="=" \'�\') null; longest_prefix="(char*)" calloc 1, sizeof(char)); longest_prefix[i]="word[i];" longest_prefix[len]="�" branch_idx="check_divergence(flag," longest_prefix) (branch_idx>= 0) { longest_prefix[branch_idx] = '�'; longest_prefix = (char*) realloc (longest_prefix, (branch_idx + 1) * sizeof(char)); } return longest_prefix; } int data_node(TrieNode* flag, char* word) { TrieNode* temp = flag; for (int i = 0; word[i]; i++) { int position = (int) word[i] - 'a'; if (temp → child[position]) { temp = temp → child[position]; } } return temp → data; } TrieNode* trie_delete(TrieNode* flag, char* word) { if (!flag) return NULL; if (!word || word[0] == '�') return flag; if (!data_node(flag, word)) { return flag; } TrieNode* temp = flag; char* longest_prefix = find_longest_prefix(flag, word); if (longest_prefix[0] == '�') { free(longest_prefix); return flag; } int i; for (i = 0; longest_prefix[i] != '�'; i++) { int position = (int) longest_prefix[i] - 'a'; if (temp → child[position] != NULL) { temp = temp → child[position]; } else { free(longest_prefix); return flag; } } int len = strlen(word); for (; i <len; i++) { int position="(int)" word[i] - \'a\'; if (temp → child[position]) trienode* rm_node="temp→child[position];" temp child[position]="NULL;" free_trienode(rm_node); } free(longest_prefix); return flag; void print_trie(trienode* flag) (!flag) return; printf(\'%c \', temp→info); for (int i="0;" < n; print_trie(temp child[i]); search(trienode* flag, char* word) printf(\'search the word %s: word); (search_trie(flag, 0) printf(\'not found
\'); else printf(\'found!
\'); main() flag="trie_make('�');" \'oh\'); \'way\'); \'bag\'); \'can\'); search(flag, \'ohh\'); \'ways\'); print_trie(flag); printf(\'
\'); printf(\'deleting \'hello\'...
\'); \'can\'...
\'); free_trienode(flag); 0; pre> <p> <strong>Output</strong> </p> <pre> Search the word ohh: Not Found Search the word bag: Found! Search the word can: Found! Search the word ways: Not Found Search the word way: Found! → h → e → l → l → o → w → a → y → i → t → e → a → b → a → g → c → a → n deleting the word 'hello'... → w → a → y → h → i → t → e → a → b → a → g → c → a → n deleting the word 'can'... → w → a → y → h → i → t → e → a → b → a → g </pre> <hr></len;></n;>