Ebben a cikkben az adatstruktúra DFS-algoritmusát tárgyaljuk. Ez egy rekurzív algoritmus, amely egy fa adatstruktúra vagy gráf összes csúcsában keres. A mélységi keresés (DFS) algoritmus a G gráf kezdeti csomópontjával kezdődik, és egyre mélyebbre megy, amíg meg nem találjuk a célcsomópontot vagy a gyermek nélküli csomópontot.
A rekurzív jelleg miatt a verem adatstruktúra használható az elosztott fájlrendszer algoritmusának megvalósítására. A DFS megvalósítási folyamata hasonló a BFS algoritmushoz.
A DFS-bejárás megvalósításának lépésenkénti folyamata a következő:
- Először is hozzon létre egy veremet a gráf csúcsainak teljes számával.
- Most válasszon egy tetszőleges csúcsot a bejárás kiindulópontjaként, és tolja be azt a csúcsot a verembe.
- Ezt követően toljon egy nem látogatott csúcsot (a verem tetején lévő csúcs mellett) a verem tetejére.
- Most ismételje meg a 3. és 4. lépést, amíg a verem tetején lévő csúcsból már nem marad meglátogatható csúcs.
- Ha nem maradt csúcs, menjen vissza, és emeljen ki egy csúcsot a veremből.
- Ismételje meg a 2., 3. és 4. lépést, amíg a köteg ki nem ürül.
DFS-algoritmus alkalmazásai
A DFS-algoritmus használatának alkalmazásai a következők:
- DFS algoritmus használható a topológiai rendezés megvalósítására.
- Két csúcs közötti utak megkeresésére használható.
- Használható ciklusok kimutatására is a grafikonon.
- A DFS-algoritmust egy megoldásos rejtvényekhez is használják.
- Az elosztott fájlrendszer annak meghatározására szolgál, hogy egy gráf kétoldalú-e vagy sem.
Algoritmus
1. lépés: ÁLLAPOT BEÁLLÍTÁSA = 1 (készenléti állapot) a G minden egyes csomópontjához
df.loc
2. lépés: Nyomja meg az A kezdő csomópontot a veremben, és állítsa be a STATUS = 2-t (várakozó állapot)
3. lépés: Ismételje meg a 4. és 5. lépést, amíg a STACK ki nem ürül
4. lépés: Nyissa ki a felső N csomópontot. Feldolgozza, és állítsa be a STATUS = 3-at (feldolgozott állapot)
5. lépés: Nyomja rá a veremre az N összes szomszédját, amely kész állapotban van (amelynek STATUS = 1), és állítsa be a STATUS = 2-t (várakozó állapot).
[HURK VÉGE]
törölje a fájlt java-ban
6. lépés: KIJÁRAT
javascript oktatóanyag
Pszeudokód
DFS(G,v) ( v is the vertex where the search starts ) Stack S := {}; ( start with an empty stack ) for each vertex u, set visited[u] := false; push S, v; while (S is not empty) do u := pop S; if (not visited[u]) then visited[u] := true; for each unvisited neighbour w of uu push S, w; end if end while END DFS() Példa DFS-algoritmusra
Most egy példa segítségével értsük meg a DFS-algoritmus működését. Az alábbi példában van egy irányított gráf, amelynek 7 csúcsa van.
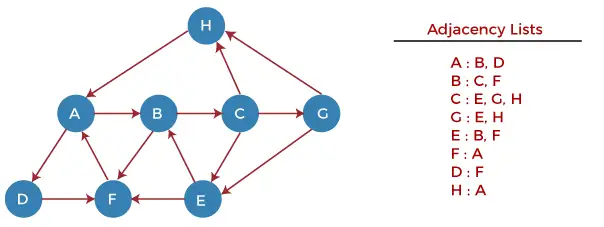
Most kezdjük el megvizsgálni a grafikont a H csomóponttól kezdve.
1. lépés - Először nyomja a H-t a veremre.
STACK: H
2. lépés - POP-olja ki a verem legfelső elemét, azaz a H-t, és nyomtassa ki. Most NYOMJA KI a H összes szomszédját a verembe, amely kész állapotban van.
Print: H]STACK: A
3. lépés - POP-olja ki a verem legfelső elemét, azaz az A-t, és nyomtassa ki. Most NYOMJA KI A minden szomszédját a verembe, amely kész állapotban van.
java string builder
Print: A STACK: B, D
4. lépés - POP-olja ki a verem legfelső elemét, azaz a D-t, és nyomtassa ki. Most NYOMJA KI D összes szomszédját a verembe, amely kész állapotban van.
Print: D STACK: B, F
5. lépés - POP a verem legfelső eleme, azaz az F, és nyomtassa ki. Most nyomja meg F összes szomszédját a verembe, amely kész állapotban van.
Print: F STACK: B
6. lépés - POP-olja ki a verem legfelső elemét, azaz a B-t, és nyomtassa ki. Most NYOMJA BE B összes szomszédját a verembe, amely kész állapotban van.
Print: B STACK: C
7. lépés - POP-olja ki a verem legfelső elemét, azaz a C-t, és nyomtassa ki. Most NYOMJA KI a C összes szomszédját a verembe, amely kész állapotban van.
Print: C STACK: E, G
8. lépés - POP a verem legfelső eleme, azaz G, és PUSH az összes G szomszédot a verembe, amelyek kész állapotban vannak.
latex szövegméret
Print: G STACK: E
9. lépés - POP a verem legfelső eleme, azaz az E és PUSH az összes E szomszédja a verembe, amely kész állapotban van.
Print: E STACK:
Most az összes gráf csomópontot bejártuk, és a verem üres.
A mélység-első keresési algoritmus összetettsége
A DFS algoritmus időbonyolultsága az O(V+E) , ahol V a csúcsok száma, E pedig a gráf éleinek száma.
A DFS-algoritmus térbonyolultsága O(V).
DFS algoritmus megvalósítása
Most pedig lássuk a DFS-algoritmus megvalósítását Java nyelven.
Ebben a példában a kód bemutatására használt grafikon a következő:

/*A sample java program to implement the DFS algorithm*/ import java.util.*; class DFSTraversal { private LinkedList adj[]; /*adjacency list representation*/ private boolean visited[]; /* Creation of the graph */ DFSTraversal(int V) /*'V' is the number of vertices in the graph*/ { adj = new LinkedList[V]; visited = new boolean[V]; for (int i = 0; i <v; i++) adj[i]="new" linkedlist(); } * adding an edge to the graph void insertedge(int src, int dest) { adj[src].add(dest); dfs(int vertex) visited[vertex]="true;" *mark current node as visited* system.out.print(vertex + ' '); iterator it="adj[vertex].listIterator();" while (it.hasnext()) n="it.next();" if (!visited[n]) dfs(n); public static main(string args[]) dfstraversal dfstraversal(8); graph.insertedge(0, 1); 2); 3); graph.insertedge(1, graph.insertedge(2, 4); graph.insertedge(3, 5); 6); graph.insertedge(4, 7); graph.insertedge(5, system.out.println('depth first traversal for is:'); graph.dfs(0); < pre> <p> <strong>Output</strong> </p> <img src="//techcodeview.com/img/ds-tutorial/28/dfs-algorithm-3.webp" alt="DFS algorithm"> <h3>Conclusion</h3> <p>In this article, we have discussed the depth-first search technique, its example, complexity, and implementation in the java programming language. Along with that, we have also seen the applications of the depth-first search algorithm.</p> <p>So, that's all about the article. Hope it will be helpful and informative to you.</p> <hr></v;>