A lineáris adatstruktúrákat úgy olvassuk be, mint egy tömb, linkelt lista, verem és sor, amelyben az összes elem szekvenciálisan van elrendezve. A különböző adatstruktúrákat különböző típusú adatokhoz használják.
Néhány tényezőt figyelembe kell venni az adatstruktúra kiválasztásakor:
Egy fa szintén a hierarchikus adatokat reprezentáló adatszerkezetek közé tartozik. Tegyük fel, hogy hierarchikus formában szeretnénk megjeleníteni az alkalmazottakat és pozícióikat, akkor az alábbiak szerint ábrázolható:
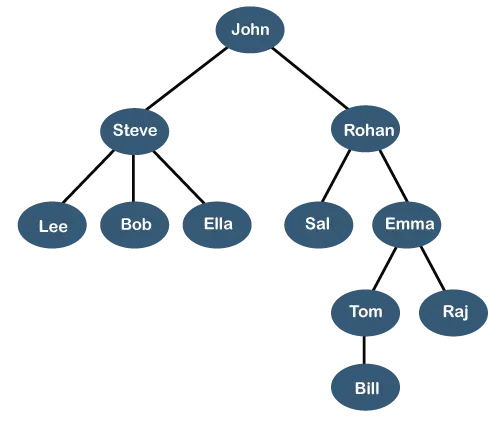
A fenti fa mutatja a szervezeti hierarchia valamelyik cégtől. A fenti szerkezetben János az a vezérigazgató a cégről, és Johnnak két közvetlen jelentése van, amelyek néven Steve és Rohan . Steve három közvetlen jelentést nevezett meg Lee, Bob, Ella ahol Steve menedzser. Bobnak két közvetlen jelentése van megnevezve Kell és Emma . Emma két közvetlen jelentéssel rendelkezik Tom és Raj . Tomnak van egy közvetlen jelentése Számla . Ezt a sajátos logikai struktúrát a Fa . Felépítése hasonló a valódi fához, ezért a nevet kapta Fa . Ebben a szerkezetben a gyökér tetején van, és ágai lefelé haladnak. Ezért elmondhatjuk, hogy a Fa adatstruktúra hatékony módja az adatok hierarchikus tárolásának.
Ismerjük meg a Fa adatstruktúra néhány kulcsfontosságú pontját.
- A fa adatszerkezet a csomópontoknak nevezett objektumok vagy entitások gyűjteménye, amelyek összekapcsolódnak a hierarchia ábrázolása vagy szimulációja céljából.
- A fa adatstruktúra nemlineáris adatstruktúra, mivel nem szekvenciálisan tárolja. Ez egy hierarchikus struktúra, mivel a fa elemei több szinten vannak elrendezve.
- A Fa adatszerkezetben a legfelső csomópont gyökércsomópontként ismert. Minden csomópont tartalmaz néhány adatot, és az adatok bármilyen típusúak lehetnek. A fenti fastruktúrában a csomópont tartalmazza az alkalmazott nevét, így az adattípus egy karakterlánc lenne.
- Minden csomópont tartalmaz néhány adatot és hivatkozást vagy hivatkozást más csomópontokhoz, amelyeket gyermeknek nevezhetünk.
A fa adatszerkezetében használt néhány alapvető kifejezés.
Tekintsük a fa szerkezetét, amely az alábbiakban látható:

A fenti struktúrában minden csomópont valamilyen számmal van címkézve. A fenti ábrán látható minden nyíl a néven ismert link a két csomópont között.
np jelent
A fa adatstruktúra tulajdonságai

A Fa adatstruktúra tulajdonságai alapján a fákat különböző kategóriákba sorolják.
cserélje ki a stringből java-ban
A Tree megvalósítása
A fa adatszerkezet a csomópontok dinamikus, pointerek segítségével történő létrehozásával hozható létre. A memóriában lévő fa az alábbiak szerint ábrázolható:

A fenti ábra a fa adatszerkezetének ábrázolását mutatja a memóriában. A fenti struktúrában a csomópont három mezőt tartalmaz. A második mező az adatokat tárolja; az első mező a bal oldali gyermek címét, a harmadik pedig a jobb oldali gyermek címét tárolja.
A programozás során egy csomópont szerkezete a következőképpen definiálható:
struct node { int data; struct node *left; struct node *right; } A fenti struktúra csak a bináris fákra definiálható, mivel a bináris fának legfeljebb két gyermeke lehet, az általános fáknak pedig kettőnél több gyermeke lehet. Az általános fák csomópontjának szerkezete eltérne a bináris fától.
A fák alkalmazásai
A fák alkalmazásai a következők:
Fa adatstruktúra típusai
A fa adatstruktúra típusai a következők:

Ott lehet n részfák száma egy általános fában. Az általános fában a részfák nincsenek rendezve, mivel a részfában lévő csomópontok nem rendezhetők.
Minden nem üres fának van lefelé mutató éle, és ezek az élek az úgynevezett csomópontokhoz kapcsolódnak gyermek csomópontok . A gyökércsomópont 0-s szinttel van címkézve. Az azonos szülővel rendelkező csomópontok neve testvérek .

Ha többet szeretne megtudni a bináris fáról, kattintson az alábbi linkre:
https://www.javatpoint.com/binary-tree
A bal oldali részfa minden csomópontjának kisebb értéket kell tartalmaznia, mint a gyökércsomópont értéke, és a jobb oldali részfa minden csomópontjának nagyobbnak kell lennie, mint a gyökércsomópont értéke.
Csomópontot létrehozhatunk egy felhasználó által definiált adattípus segítségével szerkezet, az alábbiak szerint:
struct node { int data; struct node *left; struct node *right; } A fenti a csomópont szerkezete három mezővel: adatmező, a második mező a csomópont típusú bal mutató, a harmadik mező a csomópont típusú jobb mutató.
Ha többet szeretne megtudni a bináris keresőfáról, kattintson az alábbi linkre:
https://www.javatpoint.com/binary-search-tree
Ez a bináris fa egyik típusa, vagy mondhatjuk úgy, hogy a bináris keresőfa egy változata. AVL fa kielégíti a tulajdonságát bináris fa valamint a bináris keresőfa . Ez egy önkiegyensúlyozó bináris keresőfa, amelyet a Adelson Velsky Lindas . Itt az önkiegyensúlyozás a bal oldali részfa és a jobb oldali részfa magasságának kiegyensúlyozását jelenti. Ezt a kiegyensúlyozást a kiegyenlítő tényező .
Tekinthetünk egy fát AVL-fának, ha a fa megfelel a bináris keresőfának, valamint egy kiegyenlítő tényezőnek. A kiegyenlítő tényezőt a különbség a bal oldali részfa magassága és a jobb oldali részfa magassága között . A kiegyenlítő tényező értékének 0, -1 vagy 1 kell lennie; ezért az AVL-fa minden csomópontjában a kiegyenlítési tényező értékének 0, -1 vagy 1 legyen.
Ha többet szeretne megtudni az AVL fáról, kattintson az alábbi linkre:
https://www.javatpoint.com/avl-tree
ins kulcs
A piros-fekete fa a bináris keresőfa. A piros-fekete fa előfeltétele, hogy ismernünk kell a bináris keresőfát. Egy bináris keresési fában a bal oldali részfa értékének kisebbnek kell lennie az adott csomópont értékénél, a jobb oldali részfa értékének pedig nagyobbnak kell lennie az adott csomópont értékénél. Mint tudjuk, a bináris keresés időbonyolultsága átlagos esetben log2n, a legjobb eset O(1), a legrosszabb pedig O(n).
Ha bármilyen műveletet hajtanak végre a fán, azt szeretnénk, hogy a fa kiegyensúlyozott legyen, így az összes művelet, mint a keresés, beillesztés, törlés stb., kevesebb időt vesz igénybe, és ezeknek a műveleteknek az időbeli összetettsége log2n.
A piros-fekete fa egy önkiegyensúlyozó bináris keresőfa. Az AVL fa egy magasságkiegyenlítő bináris keresési fa is miért van szükségünk vörös-fekete fára . Az AVL fában nem tudjuk, hogy hány forgatásra lenne szükség a fa kiegyensúlyozásához, de a Piros-fekete fában maximum 2 forgatás szükséges a fa kiegyensúlyozásához. Tartalmaz egy extra bitet, amely egy csomópont piros vagy fekete színét jelzi, hogy biztosítsa a fa egyensúlyát.
A megjelenítési fa adatstruktúra egyben bináris keresési fa is, amelyben a közelmúltban elért elem néhány elforgatási művelet végrehajtásával a fa gyökérpozíciójába kerül. Itt, szétszórva a nemrég elért csomópontot jelenti. Ez egy önkiegyensúlyozó bináris keresőfa, amelynek nincs kifejezett egyensúlyi feltétele, mint pl AVL fa.
Előfordulhat, hogy a splay fa magassága nincs kiegyensúlyozott, azaz a bal és a jobb oldali részfa magassága is eltérhet, de a splay fában a műveletek sorrendje nyugodt idő hol n a csomópontok száma.
A Splay fa kiegyensúlyozott fa, de nem tekinthető magasságkiegyenlített fának, mert minden egyes művelet után elforgatásra kerül, ami kiegyensúlyozott fához vezet.
Treap adatstruktúra a Tree és Heap adatstruktúrából származik. Tehát tartalmazza mind a fa, mind a kupac adatstruktúrák tulajdonságait. A bináris keresési fában a bal oldali részfa minden csomópontjának egyenlőnek vagy kisebbnek kell lennie a gyökércsomópont értékével, és a jobb oldali részfa minden csomópontjának egyenlőnek vagy nagyobbnak kell lennie a gyökércsomópont értékével. A kupac adatstruktúrában a jobb és a bal részfa is nagyobb kulcsokat tartalmaz, mint a gyökér; ezért azt mondhatjuk, hogy a gyökércsomópont tartalmazza a legalacsonyabb értéket.
A treap adatstruktúrában minden csomópont mindkettővel rendelkezik kulcs és kiemelten fontos ahol a kulcs a bináris keresési fából származik, a prioritás pedig a kupac adatstruktúrából származik.
térképes gépirat
A Treap Az adatstruktúra két tulajdonságot követ, amelyeket az alábbiakban adunk meg:
- Egy csomópont jobb gyermeke>=aktuális csomópont és egy csomópont bal gyermeke<=current node (binary tree)< li>
- Bármely részfa gyermekének nagyobbnak kell lennie, mint a csomópont (kupac)
A B-fa kiegyensúlyozott m-úton fa hol m meghatározza a fa sorrendjét. Eddig azt olvastuk, hogy a csomópont csak egy kulcsot tartalmaz, de a b-fának több kulcsa és 2 gyermeke is lehet. Mindig karbantartja a rendezett adatokat. A bináris fában lehetséges, hogy a levélcsomópontok különböző szinteken lehetnek, de a b-fában az összes levélcsomópontnak azonos szinten kell lennie.
Ha a sorrend m, akkor a csomópont a következő tulajdonságokkal rendelkezik:
- A b-fa minden csomópontjának maximuma lehet m gyermekek
- Minimális gyermekek esetén egy levélcsomópontnak 0 gyermeke van, a gyökércsomópontnak legalább 2 gyermeke van, és a belső csomópontnak legalább m/2 gyermeke van. Például az m értéke 5, ami azt jelenti, hogy egy csomópontnak 5 gyermeke lehet, és a belső csomópontok legfeljebb 3 gyermeket tartalmazhatnak.
- Minden csomópontnak maximum (m-1) kulcsa van.
A gyökércsomópontnak legalább 1 kulcsot kell tartalmaznia, és az összes többi csomópontnak legalább a kulcsot kell tartalmaznia m/2 mínusz 1 mennyezet kulcsok.