SLF4J (Simple Logging Faade for Java) egy API, amelyet arra terveztek, hogy általános hozzáférést biztosítson számos naplózási keretrendszerhez, amelyek közül a log4j az egyik.
Ez alapvetően egy absztrakciós réteg. Ez nem egy naplózási megvalósítás. Ez azt jelenti, hogy ha ír egy könyvtárat, és SLF4J-t használ, akkor ezt a könyvtárat átadhatja valaki másnak, aki kiválaszthatja, hogy melyik naplózási megvalósítást használja az SLF4J-vel, például a log4j-t vagy a Java naplózási API-t. Arra használják, hogy megakadályozzák, hogy az alkalmazások különböző naplózási API-któl függjenek, éppúgy, mint a tőlük függő könyvtárakat.
lista tömbként
Kifejtjük azonban a Log4J és az SLF4J közötti különbséget, amely csak egysoros választ érdemel. azaz maga a kérdés rossz. Az SLF4J és a Log4J különböznek egymástól, vagy nem hasonlóak. A név szerint az SLF4J egy egyszerű naplózási homlokzat a java számára. Ez nem egy naplózási komponens, és még a tényleges naplózást sem végzi el. Ez csak egy absztrakciós réteg egy mögöttes naplózási komponenshez.
Abban az esetben Log4j , ez egy naplózási összetevő, és elvégzi a naplózást. Tehát azt mondhatjuk, hogy az SLF4J és a Log4J logikailag két különböző dolog.
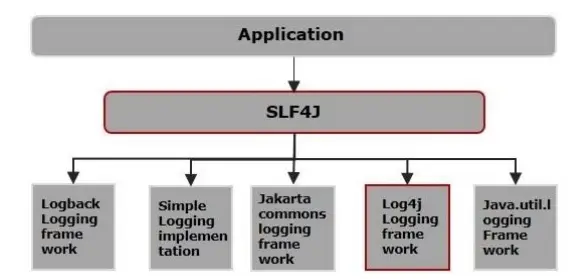
Most már csak ki kell választania, hogy melyik naplózási keretrendszert kell használnia futás közben. Ehhez két jar fájlt kell csatolnia:
- SLF4J kötési jar fájl
- A kívánt naplózási keretrendszer jar fájlok
Például a log4j használatához a projektben az alábbi jar fájlokat kell tartalmaznia:
Kat timpf ügyvéd
- slf4j-log4j12-1.7.12.jar
- log4j-1.2.17.jar
Miután mindkét jar fájlt elhelyezte az alkalmazás osztályútvonalában, az SLF4J automatikusan észleli azt, és elkezdi a log4j használatát a naplóutasítások feldolgozásához a log4j konfigurációs fájlban megadott konfiguráció alapján.
Például az alábbi kód, amit beírhat a projekt osztályfájljába:
import org.slf4j.Logger; import org.slf4j.LoggerFactory; public class HelloWorld { public static void main(String[] args) { Logger logger = LoggerFactory.getLogger(HelloWorld.class); logger.info('Hello World'); } } Miért jobb az SLF4J, mint a Log4J?
Mindig nehéz az SLF4J és a Log4j között választani. Ha van választása, azt javaslom; A naplózási absztrakció mindig előnyösebb, mint a naplózási keretrendszer. Ha naplózási absztrakciót használ, különösen az SLF4J-t, akkor áttérhetünk bármilyen naplózási keretrendszerre, amelyre a telepítéskor szükségünk van anélkül, hogy egyetlen függőséget választanánk.
Az alábbiakban felsoroljuk azokat az okokat, amelyek elég jók ahhoz, hogy az SLF4J-t válasszák a Log4j helyett:
- Mindig jobb az absztrakciót használni.
- Az SLF4J egy nyílt forráskódú vagy belső könyvtár, amely függetlenné teszi bármely konkrét naplózási megvalósítástól, ami azt jelenti, hogy nincs szükség több naplózási konfiguráció kezelésére több könyvtárhoz.
- Az SLF4J helyőrző alapú naplózást biztosít, amely javítja a kód olvashatóságát azáltal, hogy eltávolítja az olyan ellenőrzéseket, mint az isInforEnabled(), isDebugEnabled() stb.
- Az SLF4J naplózási módszerével addig halogatjuk a naplózási üzenetek (string) összeállításának költségeit, amíg szüksége van rá, ami CPU- és memóriahatékony is.
- Mivel az SLF4J kevesebb ideiglenes karakterláncot használ, kevesebb munkát jelent a szemétgyűjtő számára, ami jobb átvitelt és teljesítményt jelent az alkalmazás számára.
Tehát lényegében az SLF4J nem helyettesíti a log4j-t; mindketten együtt dolgoznak. Eltávolítja a log4j-től való függőséget az alkalmazásból, és megkönnyíti a későbbiekben a megfelelőbb könyvtárra cserélését.