A klaszterezés vagy fürtelemzés egy gépi tanulási technika, amely csoportosítja a címkézetlen adatkészletet. Úgy definiálható „Az adatpontok különböző klaszterekbe történő csoportosításának módja, amelyek hasonló adatpontokból állnak. A lehetséges hasonlóságokkal rendelkező objektumok egy olyan csoportban maradnak, amely kevésbé vagy egyáltalán nem hasonlít egy másik csoporthoz.
Ehhez hasonló mintákat talál a címkézetlen adatkészletben, például alakot, méretet, színt, viselkedést stb., és felosztja a hasonló minták jelenléte és hiánya szerint.
Linux átnevezési könyvtár
Ez egy felügyelet nélküli tanulás módszerrel, ezért az algoritmus nem rendelkezik felügyelettel, és a címkézetlen adatkészlettel foglalkozik.
A klaszterezési technika alkalmazása után minden fürt vagy csoport kap egy fürtazonosítót. Az ML rendszer ezt az azonosítót használhatja nagy és összetett adathalmazok feldolgozásának egyszerűsítésére.
A klaszterezési technikát általában használják statisztikai adatelemzés.
Megjegyzés: A klaszterezés valahol hasonló a osztályozási algoritmus , de a különbség az általunk használt adatkészlet típusában van. Az osztályozásnál a címkézett adatkészlettel, míg a klaszterezésnél a címkézetlen adatkészlettel dolgozunk.
Példa : Értsük meg a klaszterezési technikát a Mall valós példáján: Amikor felkeresünk egy bevásárlóközpontot, megfigyelhetjük, hogy a hasonló használatú dolgok egy csoportba kerülnek. Például a pólók egy részre vannak csoportosítva, a nadrágok a többi résznél, hasonlóképpen a zöldséges részeknél az alma, a banán, a mangó stb. külön részekre vannak csoportosítva, hogy könnyen tájékozódhassunk a dolgokról. A klaszterezési technika is hasonlóan működik. A klaszterezés további példái a dokumentumok téma szerinti csoportosítása.
A klaszterezési technika széles körben alkalmazható különféle feladatokban. Ennek a technikának néhány leggyakoribb felhasználási módja:
- Piaci szegmentáció
- Statisztikai adatelemzés
- Közösségi hálózat elemzése
- Képszegmentálás
- Anomália észlelése stb.
Ezen általános használaton kívül a amazon ajánlási rendszerében, hogy az ajánlásokat a múltbeli termékkeresésnek megfelelően adja meg. Netflix ezt a technikát használja arra is, hogy a megtekintési előzmények alapján a filmeket és websorozatokat ajánlja felhasználóinak.
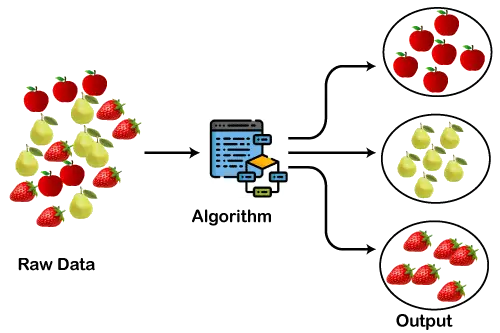
Az alábbi ábra bemutatja a klaszterezési algoritmus működését. Láthatjuk, hogy a különböző gyümölcsök több csoportra oszthatók, hasonló tulajdonságokkal.
A klaszterezési módszerek típusai
A klaszterezési módszerek nagy vonalakban fel vannak osztva Kemény klaszterezés (az adatpont csak egy csoportba tartozik) és Lágy klaszterezés (az adatpontok egy másik csoportba is tartozhatnak). De a klaszterezésnek más megközelítései is léteznek. Az alábbiakban bemutatjuk a gépi tanulásban használt fő klaszterezési módszereket:
Partícionálás Klaszterezés
Ez egyfajta fürtözés, amely az adatokat nem hierarchikus csoportokra osztja. Más néven a centroid alapú módszer . A particionálási klaszterezés leggyakoribb példája a K-Means Klaszterezési algoritmus .
Ebben a típusban az adatkészlet egy k csoportból álló halmazra van felosztva, ahol K az előre meghatározott csoportok számának meghatározására szolgál. A klaszter középpontja úgy van kialakítva, hogy az egyik klaszter adatpontjai közötti távolság minimális legyen egy másik klaszter súlypontjához képest.

Sűrűség alapú klaszterezés
A sűrűség alapú klaszterezési módszer a nagy sűrűségű területeket klaszterekbe köti, és a tetszőleges alakú eloszlásokat addig képezik, amíg a sűrű régió összekapcsolható. Ez az algoritmus az adathalmaz különböző klasztereinek azonosításával hajtja végre, és a nagy sűrűségű területeket klaszterekbe köti. Az adattérben lévő sűrű területeket ritkább területek választják el egymástól.
Ezek az algoritmusok nehézségekbe ütközhetnek az adatpontok klaszterezése során, ha az adatkészlet változó sűrűséggel és nagy dimenzióval rendelkezik.

Eloszlási modell alapú klaszterezés
Az eloszlási modell alapú klaszterezési módszerben az adatok felosztása annak a valószínűsége alapján történik, hogy egy adatkészlet hogyan tartozik egy adott eloszláshoz. A csoportosítás néhány eloszlás általános feltételezésével történik Gauss-eloszlás .
Ennek a típusnak a példája a Elvárás-maximalizálás Klaszterezési algoritmus amely Gauss-féle keverékmodelleket (GMM) használ.
tavaszi keret

Hierarchikus klaszterezés
A hierarchikus fürtözés a particionált fürtözés alternatívájaként használható, mivel nincs szükség a létrehozandó fürtök számának előzetes megadására. Ebben a technikában az adatkészletet fürtökre osztják fel, hogy egy faszerű struktúrát hozzanak létre, amelyet a dendrogram . A megfigyelések vagy tetszőleges számú klaszter kiválasztható a fa megfelelő szintű vágásával. Ennek a módszernek a leggyakoribb példája a Agglomeratív hierarchikus algoritmus .

Fuzzy Clustering
A fuzzy fürtözés olyan lágy módszer, amelyben egy adatobjektum egynél több csoporthoz vagy fürthöz is tartozhat. Minden adatkészlet rendelkezik tagsági együtthatókkal, amelyek a fürtben való tagság mértékétől függenek. Fuzzy C-means algoritmus a példa erre a fajta klaszterezésre; néha Fuzzy k-means algoritmusnak is nevezik.
Klaszterezési algoritmusok
A klaszterezési algoritmusok a fent ismertetett modelljeik alapján feloszthatók. Különféle típusú klaszterezési algoritmusok jelentek meg, de csak néhányat használnak általánosan. A klaszterezési algoritmus az általunk használt adatokon alapul. Például egyes algoritmusoknak meg kell találniuk az adott adathalmazban lévő klaszterek számát, míg másoknak meg kell találniuk az adathalmaz megfigyelése közötti minimális távolságot.
Itt elsősorban a gépi tanulásban széles körben használt fürtözési algoritmusokat tárgyaljuk:
A klaszterezés alkalmazásai
Az alábbiakban néhány általánosan ismert klaszterezési technikát mutatunk be a gépi tanulásban: