- A Redshift egy gyors és hatékony, teljesen felügyelt, petabájtos adattárház szolgáltatás a felhőben.
- Az ügyfelek óránként mindössze 0,25 dollárért használhatják a Redshiftet, kötelezettségvállalások és előzetes költségek nélkül, és terabájtonként évi 1000 dollárért petabájtra vagy még többre méretezhetik.
OLAP
Az OLAP egy Online Analytics feldolgozó rendszer által használt Vöröseltolódás .
Példa OLAP tranzakcióra:
Tegyük fel, hogy ki akarjuk számítani a digitális rádiótermék nettó nyereségét az EMEA és a csendes-óceáni térségben. Ez nagyszámú rekordot igényel. A nettó nyereség kiszámításához szükséges rekordok a következők:
- Az EMEA-ban eladott rádiók összege.
- A csendes-óceáni térségben eladott rádiók összessége.
- A rádió egységköltsége minden régióban.
- Az egyes rádiók eladási ára
- Eladási ár - egységár
Az összetett lekérdezések szükségesek a fent megadott rekordok lekéréséhez. A Data Warehous adatbázisok eltérő típusú architektúrát használnak mind adatbázis-szempontból, mind infrastruktúra rétegből.
Redshift konfiguráció
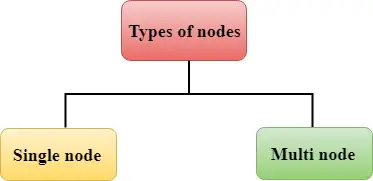
A vöröseltolódás kétféle csomópontból áll:
Egyetlen csomópont: Egy csomópont legfeljebb 160 GB-ot tárol.
Több csomópont: A több csomópont olyan csomópont, amely egynél több csomópontból áll. Két típusa van:
Kezeli az ügyfélkapcsolatokat és fogadja a lekérdezéseket. Egy vezető csomópont fogadja a lekérdezéseket az ügyfélalkalmazásoktól, elemzi a lekérdezéseket, és kidolgozza a végrehajtási terveket. Koordinálja a tervek párhuzamos végrehajtását a számítási csomóponttal, és egyesíti az összes csomópont közbenső eredményeit, majd a végeredményt visszaküldi az ügyfélalkalmazásnak.
Egy számítási csomópont végrehajtja a végrehajtási terveket, majd a köztes eredményeket elküldi a vezető csomópontnak összesítés céljából, mielőtt visszaküldené az ügyfélalkalmazásnak. Legfeljebb 128 számítási csomópontja lehet.
Ismerjük meg a vezető csomópont fogalmát és a számítási csomópontokat egy példán keresztül.
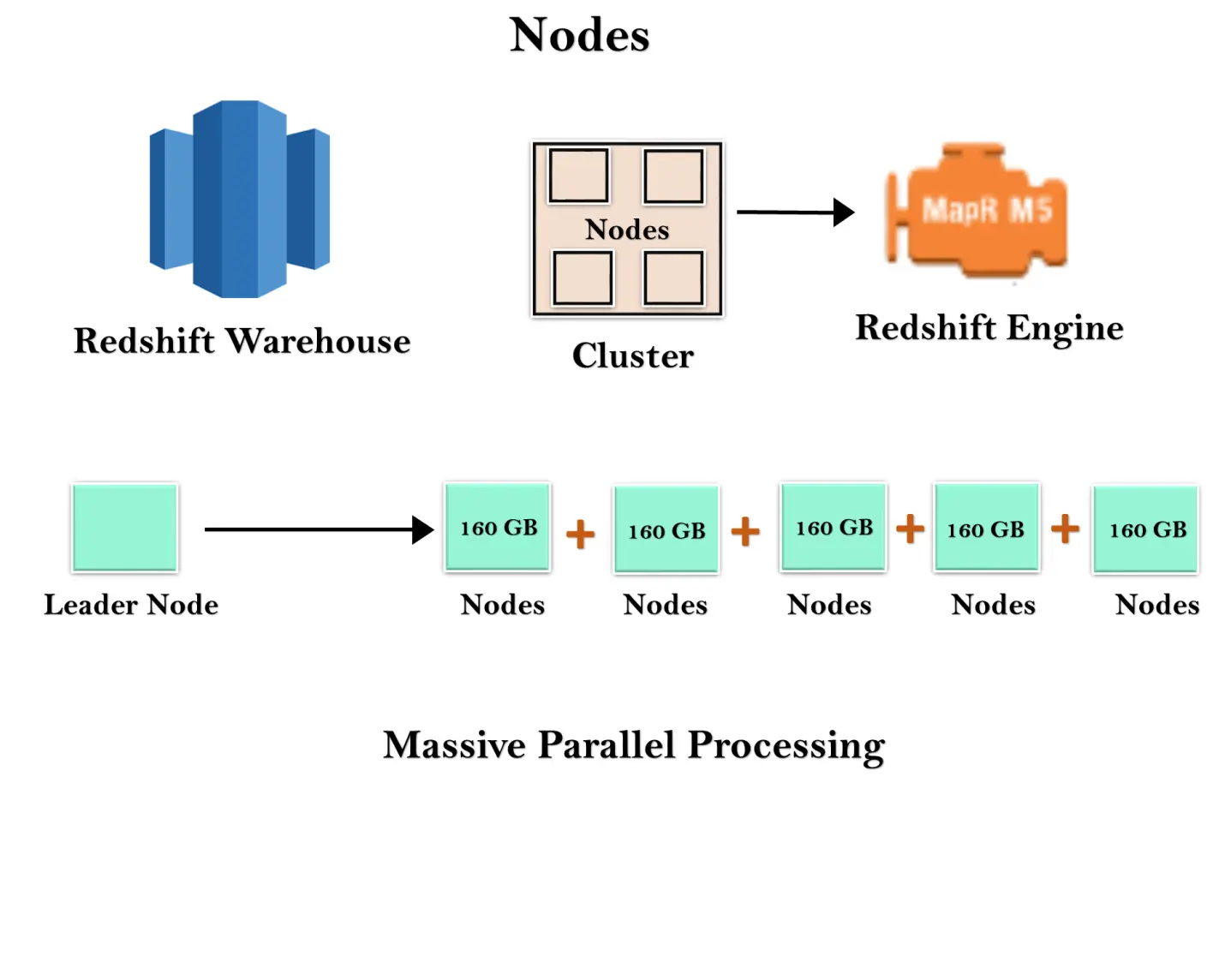
A Redshift raktár csomópontként ismert számítási erőforrások gyűjteménye, és ezek a csomópontok egy fürtként ismert csoportba vannak szervezve. Minden fürt egy Redshift Engine-ben fut, amely egy vagy több adatbázist tartalmaz.
Amikor elindít egy Redshift-példányt, az egyetlen 160 GB-os csomóponttal kezdődik. Ha növekedni szeretne, további csomópontokat vehet fel a párhuzamos feldolgozás előnyeinek kihasználása érdekében. Van egy vezető csomópontja, amely a több csomópontot kezeli. A vezető csomópont kezeli az ügyfélkapcsolatot, valamint a számítási csomópontokat. Számítási csomópontokban tárolja az adatokat, és végrehajtja a lekérdezést.
Miért a Redshift 10-szer gyorsabb?
A vöröseltolódás 10-szer gyorsabb a következő okok miatt:
Ahelyett, hogy sorokként tárolná az adatokat, az Amazon Redshift oszlopok szerint rendezi az adatokat. A soralapú rendszerek ideálisak a tranzakciók feldolgozásához, míg az oszlopalapú rendszerek ideálisak adattároláshoz és elemzéshez, ahol a lekérdezések gyakran tartalmaznak nagy adathalmazokon végrehajtott aggregátumokat. Mivel csak a lekérdezésekben érintett oszlopok kerülnek feldolgozásra, és az oszlopos adatok egymás után kerülnek tárolásra egy adathordozón, az oszlopalapú rendszerek kevesebb I/O-t igényelnek, így javul a lekérdezés teljesítménye.
Az oszlopos adattárak sokkal jobban tömöríthetők, mint a soralapú adattárak, mivel a hasonló adatok egymás után kerülnek tárolásra a lemezen. Az Amazon Redshift többféle tömörítési technikát alkalmaz, és gyakran jelentős tömörítést tud elérni a hagyományos relációs adattárolókhoz képest.
Az Amazon Redshift nem igényel indexeket vagy materializált nézeteket, így kevesebb helyet igényel, mint a hagyományos relációs adatbázisrendszerek. Amikor adatokat tölt be egy üres táblába, az Amazon Redshift automatikusan mintát vesz az adatokból, és kiválasztja a legmegfelelőbb tömörítési technikát.
Az Amazon Redshift automatikusan elosztja az adatokat, és betölti a lekérdezést a különböző csomópontok között. Az Amazon Redshift megkönnyíti új csomópontok hozzáadását az adattárházhoz, és ez lehetővé teszi számunkra, hogy gyorsabb lekérdezési teljesítményt érjünk el az adattárház növekedésével.
Vöröseltolódás jellemzői
A Redshift jellemzői az alábbiak:
lista rendezés java
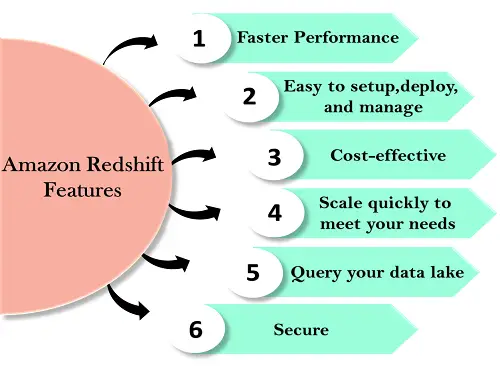
A Redshift beállítása és kezelése egyszerű. Néhány kattintással telepíthet új adattárházat az AWS-konzolon, és a Redshift automatikusan kiépíti az infrastruktúrát. Az AWS-ben minden adminisztrációs feladat automatizált, mint például a biztonsági mentések és a replikáció, ezért az adatokra kell összpontosítania, nem az adminisztrációra.
A Redshift automatikusan biztonsági másolatot készít az adatokról az S3-ba. Az S3 pillanatképeit egy másik régióban is replikálhatja a katasztrófa utáni helyreállításhoz.
Az Amazon Redshift a legköltséghatékonyabb adattárház-szolgáltatás, mivel csak azért kell fizetni, amit használ.
Költségei óránként 0,25 dollártól kezdődnek, kötelezettségvállalás és előzetes költségek nélkül, és évi 250 dollárra skálázható terabájtonként.
Az Amazon Redshift az egyetlen adattárház-szolgáltatás, amely igény szerinti árazást kínál előzetes költségek nélkül, valamint lefoglalt példányárazást is kínál, amely akár 75%-os megtakarítást is biztosít az 1-3 éves futamidő biztosításával.
A vöröseltolódás optimalizálásához a két csomópont közül választhat.
A sűrű számítási csomópont gyors CPU-k, nagy mennyiségű RAM és szilárdtestalapú lemezek használatával nagy teljesítményű adattárházakat hozhat létre.
Ha csökkenteni szeretné a költségeket, használhatja a sűrű tárolási csomópontot. Költséghatékony adattárházat hoz létre egy nagyobb merevlemez-meghajtó használatával.
Az Amazon Redshift automatikusan felfelé vagy lefelé méretezi a csomópontokat a szükséges változtatásoknak megfelelően. Csupán néhány kattintással az AWS-konzolon vagy egyetlen API-hívással könnyedén módosíthatja az adattárház csomópontjainak számát.
Ez a Redshift olyan funkciója, amely lehetővé teszi a lekérdezések futtatását exabájtnyi adattal az Amazon S3-ban. Az Amazon S3 egy biztonságos és költséghatékony adat, amellyel korlátlan számú adat tárolható nyílt formátumban.
A Redshift egyik funkciója azt jelenti, hogy a több lekérdezés ugyanazokhoz az adatokhoz férhet hozzá az Amazon S3-ban. Lehetővé teszi a lekérdezések futtatását több csomóponton, függetlenül a lekérdezés összetettségétől vagy az adatok mennyiségétől.
Az Amazon Redshift az egyetlen adattárház, amelyet az Amazon S3 Data Lake lekérdezésére használnak adatok betöltése nélkül. Ez rugalmasságot biztosít azáltal, hogy a gyakran elért adatokat a Redshiftben, a strukturálatlan vagy ritkán elérhető adatokat pedig az Amazon S3-ban tárolja.
Néhány paraméterbeállítással beállíthatja, hogy a Redshift SSL-t használjon az adatok védelmére. Engedélyezheti a titkosítást is, a lemezre írt összes adat titkosítva lesz.
Az Amazon Redshift oszlopos adattárolást, tömörítést és párhuzamos feldolgozást biztosít a lekérdezések végrehajtásához szükséges I/O mennyiségének csökkentése érdekében. Ez javítja a lekérdezés teljesítményét.