Az IDENTITY kulcsszó egy tulajdonság az SQL Serverben. Ha egy táblázatoszlop identitás tulajdonsággal van definiálva, akkor annak értéke automatikusan generált növekményes érték lesz . Ezt az értéket a szerver hozza létre automatikusan. Ezért felhasználóként nem adhatunk meg kézzel értéket egy identitásoszlopba. Ezért, ha egy oszlopot identitásként jelölünk meg, az SQL Server automatikusan növeli azt.
Szintaxis
A következő szintaxis illusztrálja az IDENTITY tulajdonság használatát az SQL Serverben:
IDENTITY[(seed, increment)]
A fenti szintaktikai paraméterek magyarázata az alábbiakban található:
Értsük meg ezt a fogalmat egy egyszerű példán keresztül.
Tegyük fel, hogy van egy Diák ' asztalra, és szeretnénk Diákigazolvány automatikusan létrejön. Nekünk van kezdő diákigazolványa 10, és minden új azonosítóval 1-gyel szeretné növelni. Ebben a forgatókönyvben a következő értékeket kell meghatározni.
Mag: 10
Növekedés: 1
CREATE TABLE Student ( StudentID INT IDENTITY(10, 1) PRIMARY KEY NOT NULL, )
MEGJEGYZÉS: Táblánként csak egy azonosító oszlop engedélyezett az SQL Serverben.
SQL Server IDENTITY Példa
Nézzük meg, hogyan használhatjuk az identitás tulajdonságot a táblázatban. Az oszlopban lévő identitástulajdonság az új tábla létrehozásakor vagy a létrehozása után állítható be. Itt mindkét esetet példákkal láthatjuk.
IDENTITY tulajdonság új táblával
A következő utasítás új táblát hoz létre az identitás tulajdonsággal a megadott adatbázisban:
CREATE TABLE person ( PersonID INT IDENTITY(10,1) PRIMARY KEY NOT NULL, Fullname VARCHAR(100) NOT NULL, Occupation VARCHAR(50), Gender VARCHAR(10) NOT NULL );
Ezután egy új sort szúrunk be ebbe a táblázatba egy KIMENET záradék az automatikusan generált személyazonosító megtekintéséhez:
INSERT INTO person(Fullname, Occupation, Gender) OUTPUT inserted.PersonID VALUES('Sara Jackson', 'HR', 'Female');
A lekérdezés végrehajtása az alábbi kimenetet jeleníti meg:
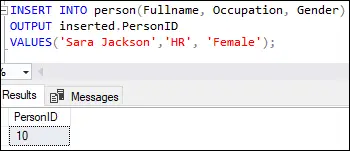
Ez a kimenet azt mutatja, hogy az első sor tízes értékkel lett beszúrva a Személyazonosító oszlopban megadottak szerint.
Szúrjunk be egy másik sort a személy asztal az alábbi:
INSERT INTO person(Fullname, Occupation, Gender) OUTPUT inserted.* VALUES('Mark Boucher', 'Cricketer', 'Male'), ('Josh Phillip', 'Writer', 'Male');
Ez a lekérdezés a következő kimenetet adja vissza:

Ez a kimenet azt mutatja, hogy a második sor 11-es, a harmadik sor pedig 12-es értékkel került beszúrásra a Személyazonosító oszlopba.
IDENTITY tulajdonság meglévő táblával
Ezt a koncepciót úgy fogjuk megmagyarázni, hogy először töröljük a fenti táblát, és identitástulajdonság nélkül hozzuk létre őket. Hajtsa végre az alábbi utasítást a táblázat eldobásához:
DROP TABLE person;
Ezután létrehozunk egy táblázatot az alábbi lekérdezéssel:
CREATE TABLE person ( Fullname VARCHAR(100) NOT NULL, Occupation VARCHAR(50), Gender VARCHAR(10) NOT NULL );
Ha egy új oszlopot szeretnénk hozzáadni az identitás tulajdonsággal egy meglévő táblához, akkor az ALTER parancsot kell használnunk. Az alábbi lekérdezés hozzáadja a PersonID-t identitásoszlopként a személytáblázathoz:
ALTER TABLE person ADD PersonID INT IDENTITY(10,1) PRIMARY KEY NOT NULL;
Érték hozzáadása az identitás oszlophoz kifejezetten
Ha új sort adunk a fenti táblázathoz az identitásoszlop értékének kifejezett megadásával, az SQL Server hibát dob. Lásd az alábbi lekérdezést:
INSERT INTO person(Fullname, Occupation, Gender, PersonID) VALUES('Mary Smith', 'Business Analyst', 'Female', 13);
A lekérdezés végrehajtása során a következő hibaüzenet jelenik meg:

Az identitásoszlop értékének explicit beszúrásához először az IDENTITY_INSERT értéket BE kell kapcsolnunk. Ezután hajtsa végre a beszúrási műveletet egy új sor hozzáadásához a táblázathoz, majd állítsa KI az IDENTITY_INSERT értéket. Lásd az alábbi kódszkriptet:
SET IDENTITY_INSERT person ON /*INSERT VALUE*/ INSERT INTO person(Fullname, Occupation, Gender, PersonID) VALUES('Mary Smith', 'Business Analyst', 'Female', 14); SET IDENTITY_INSERT person OFF SELECT * FROM person;
IDENTITY_INSERT BE lehetővé teszi a felhasználók számára, hogy adatokat helyezzenek el identitásoszlopokba, míg IDENTITY_INSERT KI megakadályozza, hogy értéket adjanak ehhez az oszlophoz.
A kódszkript végrehajtása az alábbi kimenetet jeleníti meg, ahol láthatjuk, hogy a 14-es értékű Személyazonosító sikeresen beillesztésre került.

AZONOSÍTÁS funkció
Az SQL Server néhány identitásfüggvényt biztosít a táblázat IDENTITY oszlopaival való munkavégzéshez. Ezeket az identitásfüggvényeket az alábbiakban soroljuk fel:
- @@IDENTITY funkció
- SCOPE_IDENTITY() függvény
- IDENT_CURRENT függvény
- AZONOSÍTÁS funkció
Nézzük meg néhány példával az IDENTITY függvényeket.
@@IDENTITY funkció
Az @@IDENTITY egy rendszer által meghatározott függvény, amely az utolsó azonosságértéket jeleníti meg (maximálisan használt identitásérték) létrehozva egy táblázatban az IDENTITY oszlophoz ugyanabban a munkamenetben. Ez a függvényoszlop az utasítás által generált identitásértéket adja vissza, miután új bejegyzést szúr be egy táblázatba. Visszaadja a NULLA értéket, amikor olyan lekérdezést hajtunk végre, amely nem hoz létre IDENTITY értékeket. Mindig az aktuális munkamenet hatókörében működik. Távolról nem használható.
Példa
Tegyük fel, hogy a személy táblában a jelenlegi maximális identitásérték 13. Most hozzáadunk egy rekordot ugyanabban a munkamenetben, amely eggyel növeli az identitásértéket. Ezután az @@IDENTITY függvényt fogjuk használni, hogy megkapjuk az ugyanabban a munkamenetben létrehozott utolsó identitásértéket.
Íme a teljes kódszkript:
SELECT MAX(PersonID) AS maxidentity FROM person; INSERT INTO person(Fullname, Occupation, Gender) VALUES('Brian Lara', 'Cricket', 'Male'); SELECT @@IDENTITY;
A szkript végrehajtása a következő kimenetet adja vissza, ahol láthatjuk, hogy a maximálisan használt identitásérték 14.

SCOPE_IDENTITY() függvény
A SCOPE_IDENTITY() egy rendszer által meghatározott függvény megjeleníti a legutóbbi identitásértéket táblázatban a jelenlegi hatálya alatt. Ez a hatókör lehet modul, trigger, függvény vagy tárolt eljárás. Hasonló az @@IDENTITY() függvényhez, azzal a különbséggel, hogy ennek a függvénynek csak korlátozott hatóköre van. A SCOPE_IDENTITY függvény NULL értéket ad vissza, ha az azonos hatókörben értéket generáló beszúrási művelet előtt hajtjuk végre.
Példa
Az alábbi kód az @@IDENTITY és a SCOPE_IDENTITY() függvényt is használja ugyanabban a munkamenetben. Ez a példa először az utolsó identitásértéket jeleníti meg, majd beszúr egy sort a táblázatba. Ezután mindkét identitásfüggvényt végrehajtja.
SELECT MAX(PersonID) AS maxid FROM person; INSERT INTO person(Fullname, Occupation, Gender) VALUES('Jennifer Winset', 'Actoress', 'Female'); SELECT SCOPE_IDENTITY(); SELECT @@IDENTITY;
A kód végrehajtása ugyanazt az értéket jeleníti meg az aktuális munkamenetben és hasonló hatókörben. Lásd az alábbi kimeneti képet:

Most egy példán keresztül látni fogjuk, hogy miben különbözik a két függvény. Először létrehozunk két nevű táblát munkavállalói_adatok és osztály az alábbi állítás segítségével:
CREATE TABLE employee_data ( emp_id INT IDENTITY(1, 1) PRIMARY KEY NOT NULL, fullname VARCHAR(20) NULL ) GO CREATE TABLE department ( department_id INT IDENTITY(100, 5) PRIMARY KEY, department_name VARCHAR(20) NULL );
Ezután létrehozunk egy INSERT triggert a munkavállalói_adatok táblában. Ez a trigger meghívásra kerül egy sor beszúrására a részlegtáblázatba, amikor beszúrunk egy sort a munkavállalói_adatok táblába.
Az alábbi lekérdezés létrehoz egy triggert az alapértelmezett érték beszúrásához 'AZT' a részlegtáblázatban minden egyes beszúrási lekérdezésnél a munkavállalói_adatok táblában:
ridhima tiwari
CREATE TRIGGER Insert_Department ON employee_data FOR INSERT AS BEGIN INSERT INTO department VALUES ('IT') END;
A trigger létrehozása után beszúrunk egy rekordot a munkavállalói adatok táblába, és látni fogjuk az @@IDENTITY és a SCOPE_IDENTITY() függvény kimenetét.
INSERT INTO employee_data VALUES ('John Mathew');
A lekérdezés végrehajtása hozzáad egy sort a munkavállalói_adatok táblához, és egy identitásértéket generál ugyanabban a munkamenetben. Miután a beszúrási lekérdezés végrehajtásra került a munkavállalói_adatok táblában, automatikusan meghív egy triggert, hogy hozzáadjon egy sort a részlegtáblázathoz. Az identitás kezdőértéke 1 a munkavállalói_adatok és 100 a részlegtáblázat esetében.
Végül végrehajtjuk az alábbi utasításokat, amelyek a SELECT @@IDENTITY függvény 100-as kimenetét, a SCOPE_IDENTITY függvény 1-es kimenetét jelenítik meg, mivel csak ugyanabban a hatókörben adják vissza az identitásértéket.
SELECT MAX(emp_id) FROM employee_data SELECT MAX(department_id) FROM department SELECT @@IDENTITY SELECT SCOPE_IDENTITY()
Íme az eredmény:

IDENT_CURRENT() függvény
Az IDENT_CURRENT egy rendszer által meghatározott függvény megjeleníti a legutóbbi IDENTITY értéket adott táblához bármilyen kapcsolat alatt generálva. Ez a függvény nem veszi figyelembe az identitásértéket létrehozó SQL-lekérdezés hatókörét. Ehhez a függvényhez szükség van a táblanévre, amelyhez az identitásértéket szeretnénk megkapni.
Példa
Megérthetjük, ha először kinyitjuk a két kapcsolati ablakot. Az első ablakba beszúrunk egy rekordot, amely a 15-ös identitásértéket generálja a személy táblában. Ezután ellenőrizhetjük ezt az identitásértéket egy másik kapcsolati ablakban, ahol ugyanazt a kimenetet láthatjuk. Itt a teljes kód:
1st Connection Window INSERT INTO person(Fullname, Occupation, Gender) VALUES('John Doe', 'Engineer', 'Male'); GO SELECT MAX(PersonID) AS maxid FROM person; 2nd Connection Window SELECT MAX(PersonID) AS maxid FROM person; GO SELECT IDENT_CURRENT('person') AS identity_value;
A fenti kódok végrehajtása két különböző ablakban ugyanazt az azonosító értéket jeleníti meg.

IDENTITY() függvény
Az IDENTITY() függvény egy rendszer által meghatározott függvény azonosító oszlop új táblába történő beillesztésére szolgál . Ez a függvény különbözik az IDENTITY tulajdonságtól, amelyet a CREATE TABLE és ALTER TABLE utasításokkal használunk. Ezt a függvényt csak egy SELECT INTO utasításban használhatjuk, amelyet az egyik táblából a másikba való adatátvitel során használunk.
A következő szintaxis szemlélteti ennek a függvénynek az SQL Serverben való használatát:
IDENTITY (data_type , seed , increment) AS column_name
Ha egy forrástáblának van IDENTITY oszlopa, akkor a SELECT INTO paranccsal létrehozott tábla alapértelmezés szerint örökli azt. Például , korábban létrehoztunk egy táblaszemélyt identitásoszloppal. Tegyük fel, hogy létrehozunk egy új táblát, amely örökli a személy táblát a SELECT INTO utasítások segítségével az IDENTITY() függvénnyel. Ebben az esetben hibaüzenetet kapunk, mert a forrástáblának már van identitásoszlopa. Lásd az alábbi lekérdezést:
SELECT IDENTITY(INT, 100, 2) AS NEW_ID, PersonID, Fullname, Occupation, Gender INTO person_info FROM person;
A fenti utasítás végrehajtása a következő hibaüzenetet adja vissza:

Hozzon létre egy új táblát identitástulajdonság nélkül az alábbi utasítás segítségével:
CREATE TABLE student_data ( roll_no INT PRIMARY KEY NOT NULL, fullname VARCHAR(20) NULL )
Ezután másolja ki ezt a táblázatot a SELECT INTO utasítással, beleértve az IDENTITY függvényt a következőképpen:
SELECT IDENTITY(INT, 100, 1) AS student_id, roll_no, fullname INTO temp_data FROM student_data;
Az utasítás végrehajtása után ellenőrizhetjük a sp_help parancs, amely megjeleníti a tábla tulajdonságait.

Az AZONOSÍTÁS oszlopot a KÍSÉRTHETŐ tulajdonságok a megadott feltételek szerint.
Ha ezt a függvényt a SELECT utasítással használjuk, az SQL Server a következő hibaüzenetet küldi:
177. üzenet, 15. szint, 1. állapot, 2. sor Az IDENTITY függvény csak akkor használható, ha a SELECT utasítás INTO záradékkal rendelkezik.
IDENTITY értékek újrafelhasználása
Az SQL Server táblában lévő identitásértékeket nem tudjuk újra felhasználni. Ha bármelyik sort töröljük az identitásoszlop táblájából, az identitásoszlopban rés keletkezik. Ezenkívül az SQL Server rést hoz létre, ha új sort szúrunk be az identitásoszlopba, és az utasítás meghiúsul, vagy visszagörgetjük. A hiányosság azt jelzi, hogy az identitásértékek elvesztek, és nem generálhatók újra az IDENTITY oszlopban.
Tekintsük az alábbi példát a gyakorlati megértéshez. Már van egy személytáblázatunk, amely a következő adatokat tartalmazza:

Ezután létrehozunk még két nevű táblát 'pozíció' , és ' személy_pozíció ' a következő állítás használatával:
CREATE TABLE POSITION ( PositionID INT IDENTITY (1, 1) PRIMARY KEY, Position_name VARCHAR (255) NOT NULL ); CREATE TABLE person_position ( PersonID INT, PositionID INT, PRIMARY KEY (PersonID, PositionID), FOREIGN KEY (PersonID) REFERENCES person (PersonID), FOREIGN KEY (PositionID) REFERENCES POSITION (PositionID) );
Ezután megpróbálunk egy új rekordot beszúrni a személy táblába, és hozzá kell rendelni egy pozíciót egy új sor hozzáadásával a személy_pozíció táblához. Ezt a tranzakciós nyilatkozat használatával tesszük meg az alábbiak szerint:
BEGIN TRANSACTION BEGIN TRY -- insert a new row into the person table INSERT INTO person (Fullname, Occupation, Gender) VALUES('Joan Smith', 'Manager', 'Male'); -- assign a position to a new person INSERT INTO person_position (PersonID, PositionID) VALUES(@@IDENTITY, 10); END TRY BEGIN CATCH IF @@TRANCOUNT > 0 ROLLBACK TRANSACTION; END CATCH IF @@TRANCOUNT > 0 COMMIT TRANSACTION;
A fenti tranzakciókód szkript sikeresen végrehajtja az első insert utasítást. De a második állítás meghiúsult, mivel a pozíciótáblázatban nem volt tízes azonosítójú pozíció. Ezért az egész tranzakciót visszaállították.
Mivel a Személyazonosító oszlopban a maximális identitásértékünk 16, az első insert utasítás a 17-es identitásértéket használta fel, majd a tranzakció visszaállításra került. Ezért, ha beszúrjuk a következő sort a Személy táblába, akkor a következő identitásérték 18 lesz. Hajtsa végre az alábbi utasítást:
INSERT INTO person(Fullname, Occupation, Gender) VALUES('Peter Drucker',' Writer', 'Female');
A személytábla újbóli ellenőrzése után azt látjuk, hogy az újonnan hozzáadott rekord 18-as identitásértéket tartalmaz.

Két IDENTITY oszlop egyetlen táblázatban
Technikailag nem lehetséges egyetlen táblában két identitásoszlopot létrehozni. Ha ezt tesszük, az SQL Server hibát jelez. Lásd a következő lekérdezést:
CREATE TABLE TwoIdentityTable ( ID1 INT IDENTITY (10, 1) NOT NULL, ID2 INT IDENTITY (100, 1) NOT NULL )
Amikor ezt a kódot végrehajtjuk, a következő hibát fogjuk látni:

A számított oszlop használatával azonban létrehozhatunk két identitásoszlopot egyetlen táblában. A következő lekérdezés létrehoz egy táblázatot egy számított oszloppal, amely az eredeti identitásoszlopot használja, és 1-gyel csökkenti azt.
CREATE TABLE TwoIdentityTable ( ID1 INT IDENTITY (10, 1) NOT NULL, SecondID AS 10000-ID1, Descriptions VARCHAR(60) )
Ezután hozzáadunk néhány adatot ebbe a táblázatba az alábbi paranccsal:
INSERT INTO TwoIdentityTable (Descriptions) VALUES ('Javatpoint provides best educational tutorials'), ('www.javatpoint.com')
Végül a SELECT utasítás segítségével ellenőrizzük a táblázat adatait. A következő kimenetet adja vissza:

A képen láthatjuk, hogy a SecondID oszlop második identitásoszlopként működik, tízzel csökkenve a 9990-es kiindulási értékről.
Az SQL Server IDENTITY oszlopával kapcsolatos tévhitek
A DBA-felhasználónak sok tévhite van az SQL Server identitásoszlopaival kapcsolatban. Az alábbiakban felsoroljuk azokat a leggyakoribb félreértéseket, amelyek az identitásoszlopokkal kapcsolatban megjelennek:
Az IDENTITY oszlop EGYEDI: Az SQL Server hivatalos dokumentációja szerint az identitás tulajdonság nem garantálhatja, hogy az oszlop értéke egyedi. Az oszlop egyediségének érvényesítéséhez PRIMARY KEY-t, EGYEDI kényszert vagy EGYEDI indexet kell használnunk.
Az IDENTITY oszlop egymást követő számokat generál: A hivatalos dokumentáció egyértelműen kimondja, hogy az identitásoszlopban hozzárendelt értékek elveszhetnek adatbázis-hiba vagy a szerver újraindításakor. Ez hézagokat okozhat az identitásértékben a beillesztés során. A rés akkor is létrejöhet, ha töröljük az értéket a táblából, vagy az insert utasítást visszagurítjuk. A hézagokat generáló értékek nem használhatók tovább.
Az IDENTITY oszlop nem tudja automatikusan létrehozni a meglévő értékeket: Az identitásoszlop nem generálhat automatikusan meglévő értékeket mindaddig, amíg az identitástulajdonság újra nem kerül a DBCC CHECKIDENT paranccsal. Lehetővé teszi az identitás tulajdonság kezdőértékének (a sor kezdőértékének) beállítását. A parancs végrehajtása után az SQL Server nem ellenőrzi a táblázatban már meglévő újonnan létrehozott értékeket.
Az IDENTITY oszlop, mint ELSŐDLEGES KULCS, elegendő a sor azonosításához: Ha egy elsődleges kulcs minden egyéb egyedi megkötés nélkül tartalmazza az identitásoszlopot a táblázatban, az oszlop duplikált értékeket tárolhat, és megakadályozhatja az oszlop egyediségét. Mint tudjuk, az elsődleges kulcs nem tud duplikált értékeket tárolni, az identitás oszlop viszont képes duplikált értékeket tárolni; nem javasolt az elsődleges kulcs és az identitás tulajdonság használata ugyanabban az oszlopban.
Rossz eszköz használata az identitásértékek visszaállításához egy beszúrás után: Gyakori tévhit az is, hogy nem ismerjük az @@IDENTITY, SCOPE_IDENTITY(), IDENT_CURRENT és IDENTITY() függvények közötti különbségeket, hogy az identitásértéket közvetlenül beszúrjuk az imént végrehajtott utasításból.
A SEQUENCE és az IDENTITY közötti különbség
Az automatikus számok generálásához mind a SEQUENCE-t, mind az IDENTITY-t használjuk. Van azonban néhány eltérése, és a fő különbség az, hogy az azonosság táblafüggő, míg a sorrend nem. Foglaljuk össze táblázatos formában különbségeiket:
| IDENTITÁS | SORREND |
|---|---|
| Az identitás tulajdonság egy adott táblához használatos, és nem osztható meg más táblákkal. | A DBA határozza meg azt a sorozatobjektumot, amely több tábla között is megosztható, mivel független a táblától. |
| Ez a tulajdonság automatikusan generál értékeket minden alkalommal, amikor az insert utasítás végrehajtásra kerül a táblán. | A NEXT VALUE FOR záradékot használja a sorozatobjektum következő értékének generálásához. |
| Az SQL Server nem állítja vissza az identitástulajdonság oszlopértékét a kezdeti értékre. | Az SQL Server visszaállíthatja a sorozatobjektum értékét. |
| Nem tudjuk beállítani az identitástulajdonság maximális értékét. | Beállíthatjuk a sorozat objektum maximális értékét. |
| Az SQL Server 2000-ben került bevezetésre. | Az SQL Server 2012-ben kerül bevezetésre. |
| Ez a tulajdonság nem tud identitásértéket generálni csökkenő sorrendben. | Csökkenő sorrendben tud értékeket generálni. |
Következtetés
Ez a cikk teljes áttekintést nyújt az SQL Server IDENTITY tulajdonságáról. Itt megtanultuk, hogyan és mikor használják az identitástulajdonságot, annak különböző funkcióit, tévhiteket, és miben tér el a sorozattól.