Ebben a cikkben a BFS-algoritmust tárgyaljuk az adatstruktúrában. A Breadth-first keresés egy gráfbejárási algoritmus, amely a gyökércsomóponttól kezdi meg a gráf bejárását, és feltárja az összes szomszédos csomópontot. Ezután kiválasztja a legközelebbi csomópontot, és feltárja az összes feltáratlan csomópontot. Ha a bejáráshoz BFS-t használunk, a gráf bármely csomópontja gyökércsomópontnak tekinthető.
A gráf bejárásának számos módja van, de ezek közül a BFS a leggyakrabban használt megközelítés. Ez egy rekurzív algoritmus, amely egy fa vagy gráf adatstruktúra összes csúcsában keres. A BFS a gráf minden csúcsát két kategóriába sorolja – látogatott és nem látogatott. Kijelöl egy csomópontot a grafikonon, és ezt követően felkeresi a kiválasztott csomóponttal szomszédos összes csomópontot.
A BFS algoritmus alkalmazásai
A szélesség-első-algoritmus alkalmazásai a következők:
- A BFS segítségével meg lehet találni a szomszédos helyeket egy adott forráshelyről.
- Peer-to-peer hálózatban a BFS algoritmus bejárási módszerként használható az összes szomszédos csomópont megtalálásához. A legtöbb torrent kliens, mint például a BitTorrent, uTorrent stb., ezt a folyamatot alkalmazza a 'magok' és a 'társ' megtalálására a hálózatban.
- A BFS a webrobotokban használható weboldal-indexek létrehozására. Ez az egyik fő algoritmus, amely weboldalak indexelésére használható. A bejárást a forrásoldalról kezdi, és követi az oldalhoz kapcsolódó hivatkozásokat. Itt minden weboldal csomópontnak számít a grafikonon.
- A BFS a legrövidebb út és a minimális feszítőfa meghatározására szolgál.
- A BFS-t Cheney technikájában is használják a szemétgyűjtés megkettőzésére.
- Használható a ford-Fulkerson módszerben a maximális áramlás kiszámítására egy áramlási hálózatban.
Algoritmus
A gráf feltárásához szükséges BFS-algoritmus lépései a következők:
1. lépés: ÁLLAPOT BEÁLLÍTÁSA = 1 (készenléti állapot) a G minden csomópontjához
2. lépés: Állítsa sorba az A kezdő csomópontot, és állítsa STATUS = 2 értékre (várakozó állapot)
3. lépés: Ismételje meg a 4. és 5. lépést, amíg a QUEUE ki nem ürül
4. lépés: Állítson fel egy N csomópontot a sorba. Feldolgozza és állítsa STATUS = 3 értékre (feldolgozott állapot).
farkas vagy róka
5. lépés: Állítsa sorba N összes szomszédját, amely kész állapotban van (amelyiknek STATUS = 1), és állítsa be
állapotuk = 2
(várakozó állapot)
[HURK VÉGE]
6. lépés: KIJÁRAT
Példa a BFS algoritmusra
Most egy példa segítségével értsük meg a BFS-algoritmus működését. Az alábbi példában van egy irányított gráf, amelynek 7 csúcsa van.
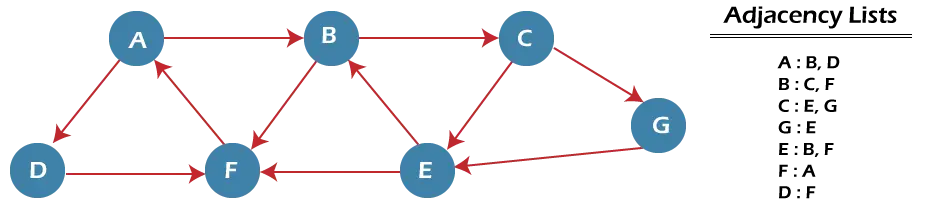
A fenti grafikonon a 'P' minimális elérési út az A csomóponttól induló és az E csomópontnál végződő BFS használatával található meg. Az algoritmus két sort használ, nevezetesen QUEUE1 és QUEUE2. A QUEUE1 tartalmazza az összes feldolgozandó csomópontot, míg a QUEUE2 tartalmazza az összes feldolgozott és a QUEUE1-ből törölt csomópontot.
Most kezdjük el megvizsgálni a grafikont az A csomóponttól kezdve.
1. lépés - Először adjon A-t a queue1-hez és NULL-t a queue2-hez.
QUEUE1 = {A} QUEUE2 = {NULL} 2. lépés - Most törölje az A csomópontot az 1. sorból, és adja hozzá a 2. sorhoz. Szúrja be az A csomópont összes szomszédját az 1. sorba.
QUEUE1 = {B, D} QUEUE2 = {A} 3. lépés - Most törölje a B csomópontot az 1. sorból, és adja hozzá a 2. sorhoz. Illessze be a B csomópont összes szomszédját a queue1-be.
QUEUE1 = {D, C, F} QUEUE2 = {A, B} 4. lépés - Most törölje a D csomópontot az 1. sorból, és adja hozzá a 2. sorhoz. Szúrja be a D csomópont összes szomszédját az 1. sorba. A D csomópont egyetlen szomszédja az F, mivel az már be van illesztve, így nem kerül be újra.
QUEUE1 = {C, F} QUEUE2 = {A, B, D} 5. lépés - Törölje a C csomópontot az 1. sorból, és adja hozzá a 2. sorhoz. Illessze be a C csomópont összes szomszédját a queue1-be.
QUEUE1 = {F, E, G} QUEUE2 = {A, B, D, C} 5. lépés - Törölje az F csomópontot az 1. sorból, és adja hozzá a 2. sorhoz. Szúrja be az F csomópont összes szomszédját a queue1-be. Mivel az F csomópont összes szomszédja már jelen van, nem illesztjük be őket újra.
QUEUE1 = {E, G} QUEUE2 = {A, B, D, C, F} 6. lépés - Törölje az E csomópontot az 1. sorból. Mivel az összes szomszédja már fel lett adva, ezért nem illesztjük be újra. Most az összes csomópontot meglátogatjuk, és az E célcsomópontot a queue2-ben találjuk.
QUEUE1 = {G} QUEUE2 = {A, B, D, C, F, E} A BFS algoritmus összetettsége
A BFS időbeli összetettsége a grafikon ábrázolásához használt adatszerkezettől függ. A BFS algoritmus időbonyolultsága a O(V+E) , mivel a legrosszabb esetben a BFS algoritmus minden csomópontot és élt megvizsgál. Egy gráfban a csúcsok száma O(V), míg az élek száma O(E).
A BFS térkomplexitása így fejezhető ki O(V) , ahol V a csúcsok száma.
BFS algoritmus megvalósítása
Most pedig lássuk a BFS algoritmus megvalósítását java-ban.
java listát rendez
Ebben a kódban a szomszédsági listát használjuk a gráfunk ábrázolására. A Breadth-First Search algoritmus Java-ban való megvalósítása sokkal egyszerűbbé teszi a szomszédsági lista kezelését, mivel csak akkor kell végighaladnunk az egyes csomópontokhoz csatolt csomópontok listáján, ha a csomópont kikerül a sorból a sor elején (vagy elején).
Ebben a példában a kód bemutatására használt grafikon a következő:

import java.io.*; import java.util.*; public class BFSTraversal { private int vertex; /* total number number of vertices in the graph */ private LinkedList adj[]; /* adjacency list */ private Queue que; /* maintaining a queue */ BFSTraversal(int v) { vertex = v; adj = new LinkedList[vertex]; for (int i=0; i<v; i++) { adj[i]="new" linkedlist(); } que="new" void insertedge(int v,int w) adj[v].add(w); * adding an edge to the adjacency list (edges are bidirectional in this example) bfs(int n) boolean nodes[]="new" boolean[vertex]; initialize array for holding data int a="0;" nodes[n]="true;" que.add(n); root node is added top of queue while (que.size() !="0)" n="que.poll();" remove element system.out.print(n+' '); print (int i="0;" < adj[n].size(); iterate through linked and push all neighbors into if (!nodes[a]) only insert nodes they have not been explored already nodes[a]="true;" que.add(a); public static main(string args[]) bfstraversal graph="new" bfstraversal(10); graph.insertedge(0, 1); 2); 3); graph.insertedge(1, graph.insertedge(2, 4); graph.insertedge(3, 5); 6); graph.insertedge(4, 7); graph.insertedge(5, graph.insertedge(6, graph.insertedge(7, 8); system.out.println('breadth first traversal is:'); graph.bfs(2); pre> <p> <strong>Output</strong> </p> <img src="//techcodeview.com/img/ds-tutorial/64/bfs-algorithm-3.webp" alt="Breadth First Search Algorithm"> <h3>Conclusion</h3> <p>In this article, we have discussed the Breadth-first search technique along with its example, complexity, and implementation in java programming language. Here, we have also seen the real-life applications of BFS that show it the important data structure algorithm.</p> <p>So, that's all about the article. Hope, it will be helpful and informative to you.</p> <hr></v;>